서론
인공지능 기술이 발달하면서 다양한 분야에 응용되고 있다. 그중에서도 순환 신경망(Recurrent Neural Network, RNN)은 시계열 데이터 처리에 탁월한 성능을 보이며, 자연어 처리, 음성 인식, 시계열 예측 등 다양한 분야에 활용되고 있다. RNN은 기존의 피드포워드 신경망과는 달리 은닉층의 출력이 다음 시점의 입력에 영향을 미치는 구조를 가지고 있다. 이를 통해 시계열 데이터의 특성을 효과적으로 학습할 수 있다. RNN에 대해 알아보자.
RNN
RNN(Recurrent Neural Network)은 인공신경망의 한 종류로, 순환 구조를 가진 신경망 모델이다. 기존의 피드포워드 신경망과 달리 RNN은 은닉층의 출력이 다음 시점의 입력에 영향을 미치는 특징을 가지고 있다.
RNN의 주요 특징은 다음과 같다. 첫째, 순환 구조로 인해 은닉층의 출력이 다음 시점의 입력으로 사용되어 시간적 의존성을 모델링할 수 있다. 둘째, 이전 시점의 정보를 저장하고 활용할 수 있는 메모리 기능을 가지고 있어 장기 의존성 문제를 해결할 수 있다. 셋째, 가변 길이의 입력 데이터를 처리할 수 있어 자연어 처리, 음성 인식 등 다양한 분야에서 유용하게 활용된다.
RNN은 시계열 데이터 처리, 언어 모델링, 기계 번역, 음성 인식 등 다양한 분야에서 뛰어난 성능을 보이며, 최근 딥러닝 기술의 발전과 함께 널리 사용되고 있다.
CBOW 모델

CBOW(Continuous Bag-of-Words) 모델은 단어 임베딩 기법 중 하나로, 주변 단어들을 입력으로 받아 중심 단어를 예측하는 모델이다. CBOW 모델은 단어의 문맥 정보를 활용하여 단어 임베딩을 학습한다. 모델의 입력은 주변 단어들의 평균 임베딩 벡터이며, 출력은 중심 단어의 임베딩 벡터이다. 즉, CBOW 모델은 주변 단어들로부터 중심 단어를 예측하는 것을 목표로 한다.
CBOW 모델의 학습 과정은 다음과 같다. 첫째, 입력 단어들의 임베딩 벡터를 평균하여 하나의 입력 벡터를 생성한다. 둘째, 이 입력 벡터를 이용하여 중심 단어의 임베딩 벡터를 예측한다. 셋째, 예측된 벡터와 실제 중심 단어의 임베딩 벡터 간의 오차를 최소화하는 방향으로 모델 매개변수를 업데이트한다.(즉, 단어 나열에 확률을 부여)
CBOW 모델((조건부) 언어모델의 근사)은 단어의 문맥 정보를 효과적으로 학습할 수 있어 자연어 처리 분야에서 널리 사용되고 있다. 또한 학습된 단어 임베딩은 다양한 응용 분야에서 유용하게 활용될 수 있다.
CBOW 모델의 한계
1. 고정된 window size
- CBOW 모델은 주변 단어를 고정된 window size로 고려한다.
- 이는 문맥의 길이가 다양한 실제 상황을 잘 반영하지 못할 수 있다.
- 문맥의 길이가 고정된 window size보다 길거나 짧은 경우, 중요한 정보를 놓칠 수 있다.
2. 맥락 단어 순서가 무시됨.
- CBOW 모델은 주변 단어들의 순서 정보를 고려하지 않고, 단순히 평균 임베딩을 사용한다.
- 이로 인해 단어의 문맥적 의미를 정확히 포착하기 어려울 수 있다.
- 예를 들어 "good morning"과 "morning good"은 서로 다른 의미를 가지지만, CBOW 모델에서는 유사한 임베딩을 갖게 된다.
이러한 한계를 극복하기 위해 Skip-gram 모델과 같은 다른 단어 임베딩 기법들이 제안되었다. 또한 최근에는 문맥을 고려한 언어 모델(BERT 등)이 개발되어 이러한 한계를 극복하고자 하는 노력이 이루어지고 있다.
RNN: Recurrent Neural Network (순환 신경망)
RNN은 과거 정보를 기억하고 동시에 현재 입력과 함께 처리할 수 있는 순환 구조(닫힌 경로)를 가지고 있다. 이를 통해 최신 데이터를 빠르게 갱신할 수 있어 시계열 데이터 처리에 강점을 가지며, 언어 모델링, 음성 인식, 기계 번역 등 다양한 분야에 활용된다.
RNN의 학습 알고리즘
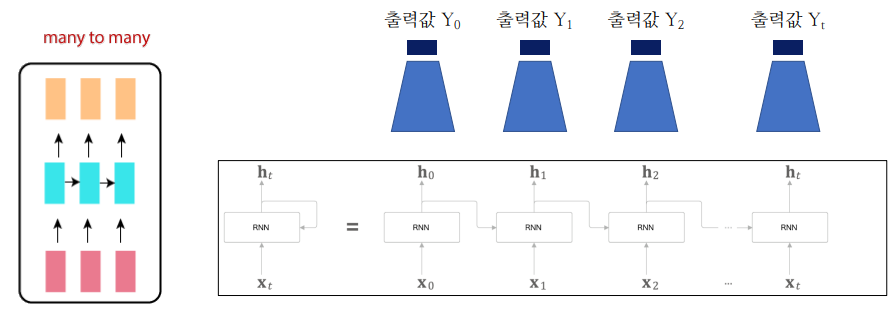
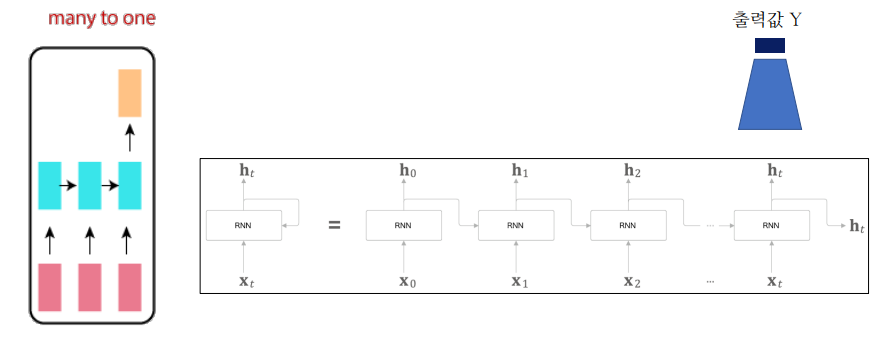
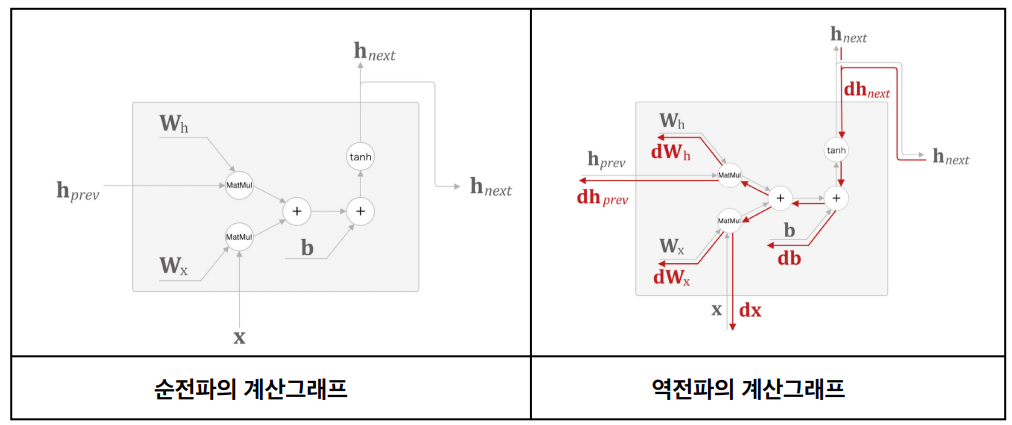
이전까지는 위와 같은 순환신경망의 전파를 주로 이용했었다.
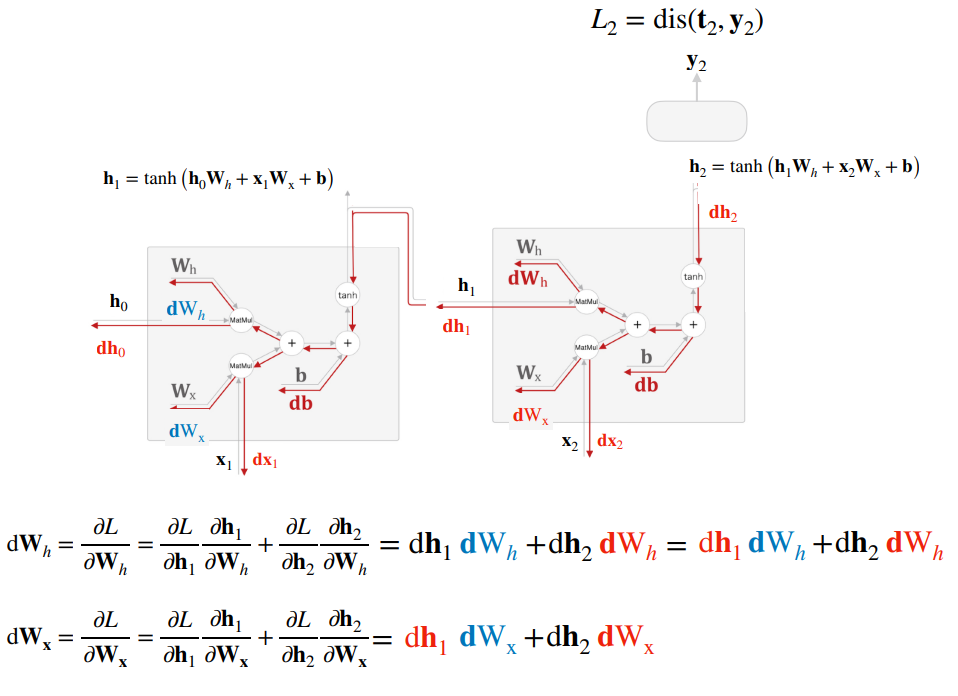
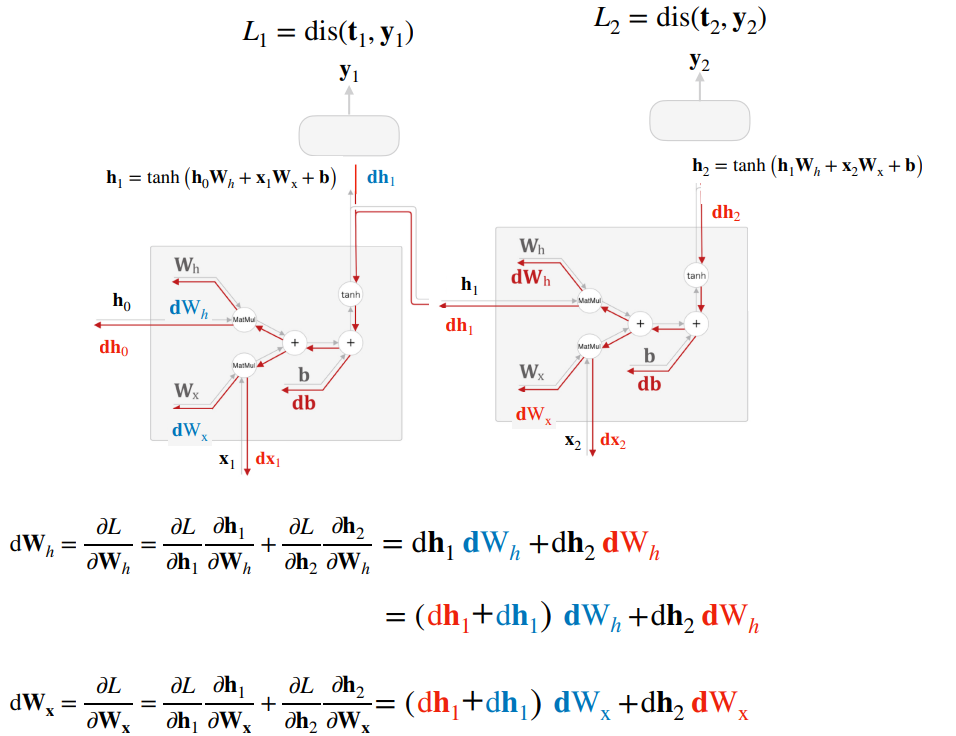
그러나 RNN의 학습은 주로 BPTT (순환신경망의 역전파, Back-Propagation Through Time) 알고리즘을 사용한다. BPTT는 시간에 따른 그래프 구조를 따라 오차를 역전 파하여 가중치를 업데이트하는 방식이다. 하지만 BPTT는 장기 의존성 문제로 인해 기울기 소실 및 폭발 문제가 발생할 수 있다.
RNN 문제
BPTT의 기울기 소실과 기울기 폭발
그러나 순환신경망 역전파(BPTT)에도 기울기 소실과 폭발 문제가 있다.
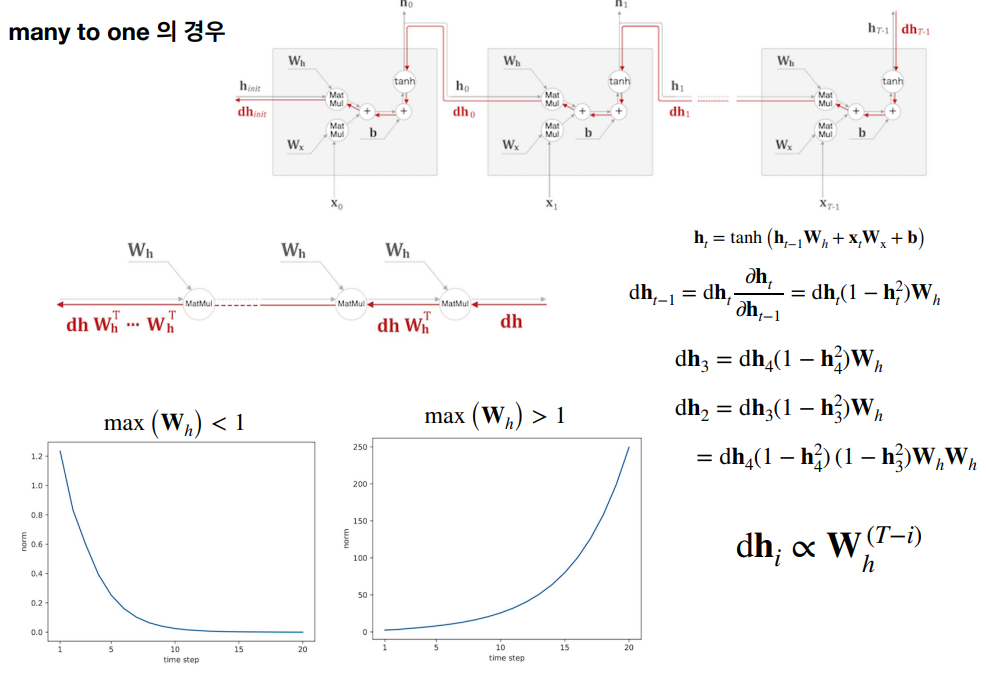
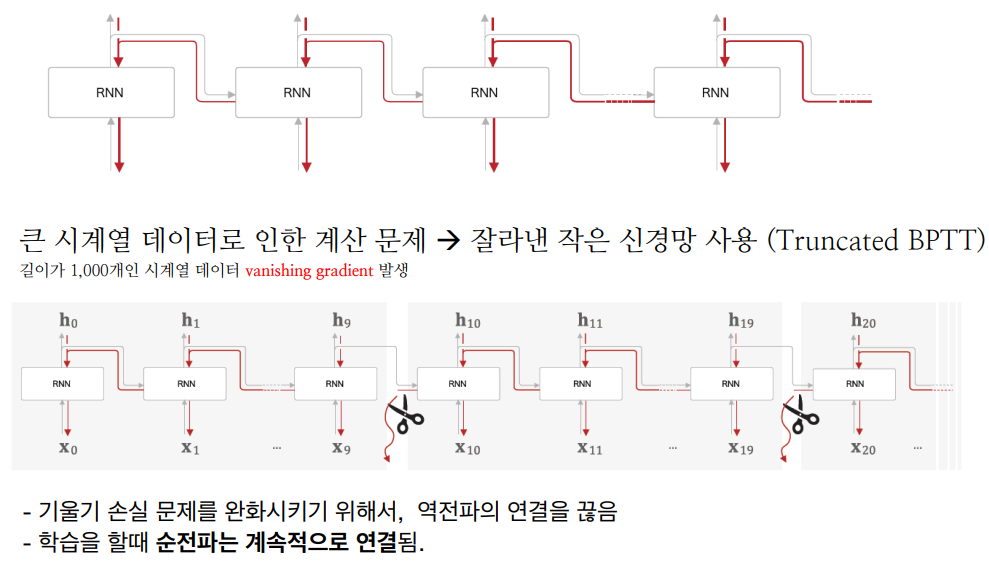
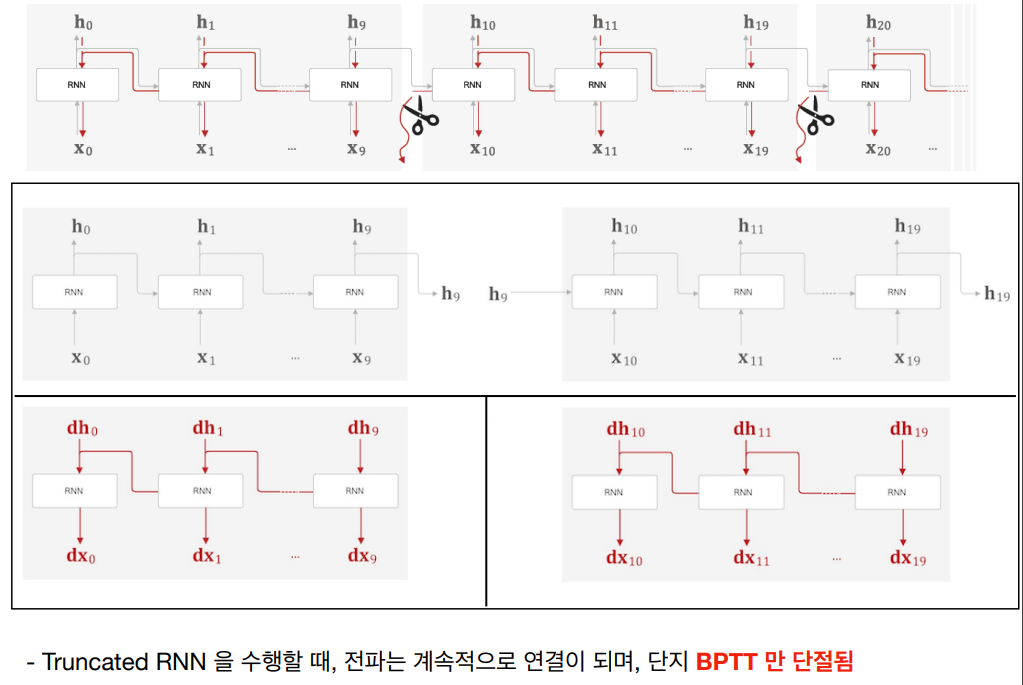
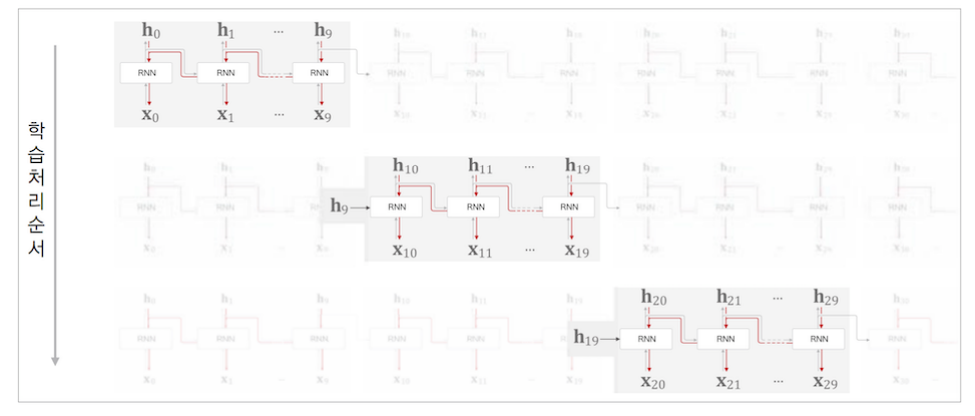
기울기 소실 문제는 시간이 지남에 따라 오차 신호가 점점 작아지는 현상이다. 이로 인해 초기 시점의 가중치 업데이트가 매우 작아져 학습이 잘 이루어지지 않는다. 이 문제는 활성화 함수로 시그모이드나 tanh 함수를 사용할 때 더 심각해진다. 기울기 폭발 문제는 기울기 소실과 반대로 오차 신호가 점점 커지면서 매우 큰 값을 갖게 되는 현상이 발생한다. 이로 인해 가중치 업데이트가 너무 크게 이루어져 모델이 불안정해지고 발산할 수 있다. 이 문제는 모델의 복잡도가 높거나 입력 데이터의 특성이 좋지 않을 때 더 자주 발생한다. 이를 해결하고자 긴 시계열 데이터를 일정 길이로 잘라내어 처리함으로써 계산 비용을 줄이고 기울기 소실/폭발 문제를 완화할 수 있는 Truncated BPTT 개념을 사용한다. 혹은 역전파 시 일정 시점에서 연결을 끊어 기울기 소실/폭발을 방지할 수 있다.
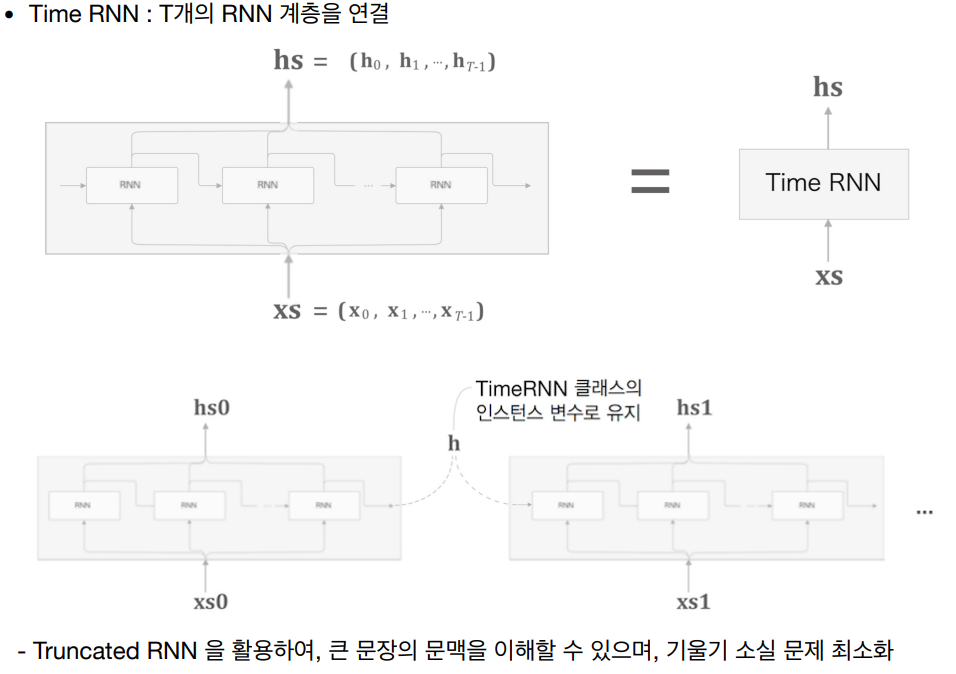
대표적인 해결 방법으로는 LSTM(Long Short-Term Memory)이나 GRU(Gated Recurrent Unit)와 같은 개선된 순환 신경망 구조의 사용, 정규화 기법 적용, 초기화 방법 개선 등이 있다. 이를 통해 순환 신경망의 학습 안정성과 성능을 크게 향상할 수 있습니다. 아래에서 자세히 살펴보자.
RNNLM (Recurrent Neural Network Language Model)
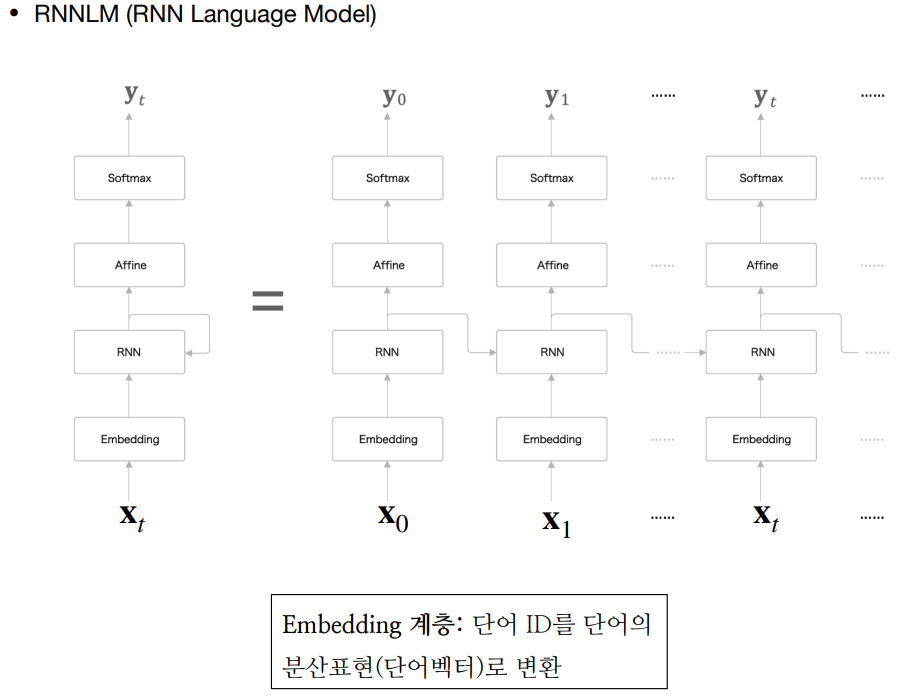
RNNLM은 RNN 구조를 활용한 언어 모델이다. 임베딩 계층이란 단어 ID를 단어의 분산 표현(단어 벡터)으로 변환하여 RNN에 입력하는 것을 말한다. 즉, 지금까지 입력된 단어 정보를 기억하고, 다음에 출현할 단어를 예측하는 RNN을 이용하여 RNNLM은 문장 생성, 기계 번역, 대화 시스템 등에 활용된다.
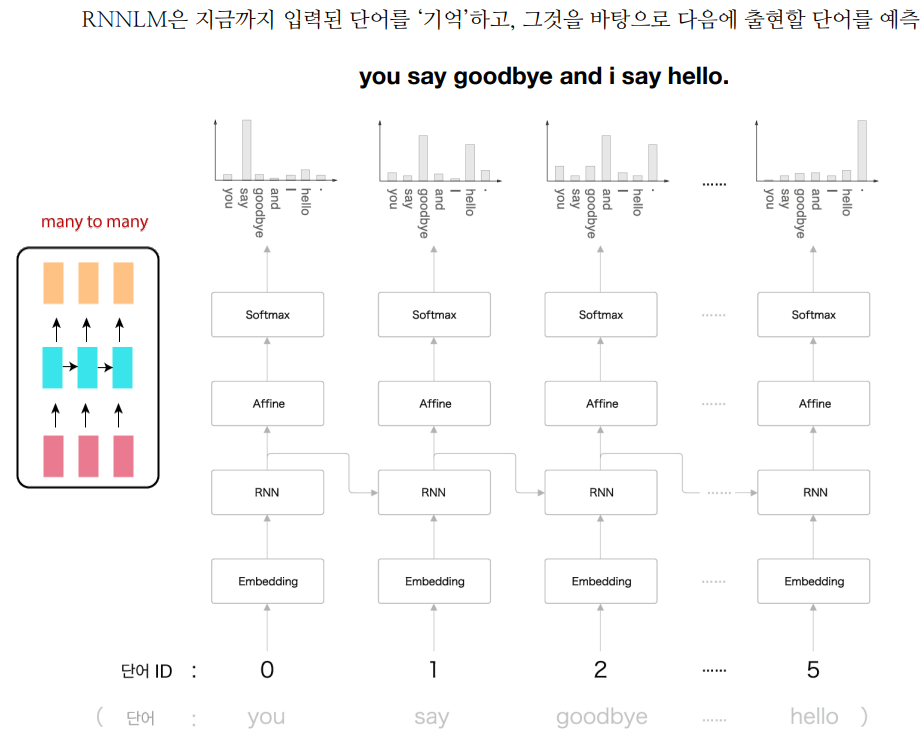
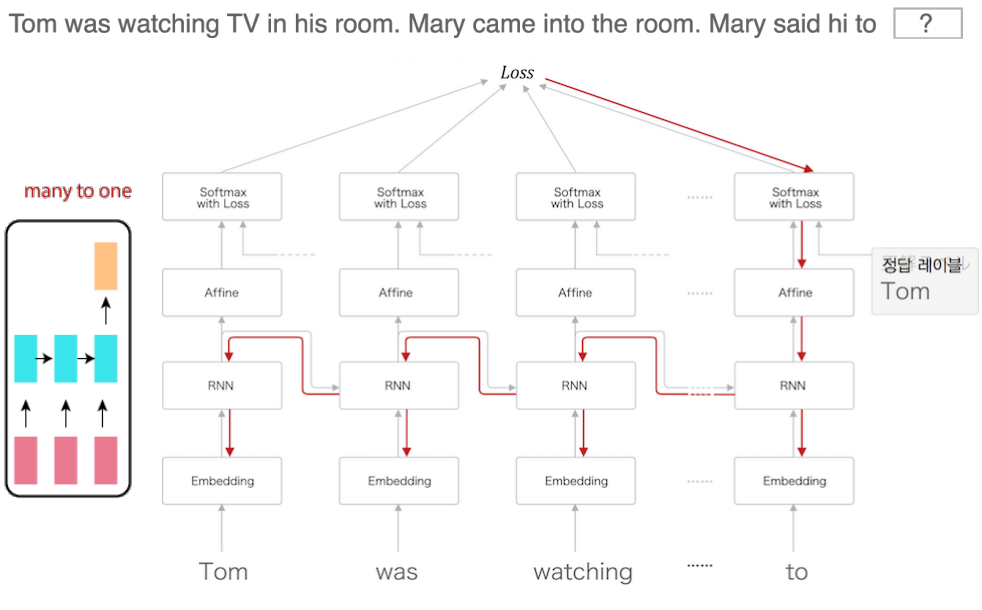
RNN 문제 해결
4. 기울기 문제가 생기지 않는 이유:
- LSTM과 GRU는 기울기 소실 및 폭발 문제를 해결하기 위해 설계된 모델
- 게이트 메커니즘을 통해 장기 기억과 단기 기억을 선택적으로 관리하여 기울기 문제를 방지
RNN 기울기 폭발 대책 1
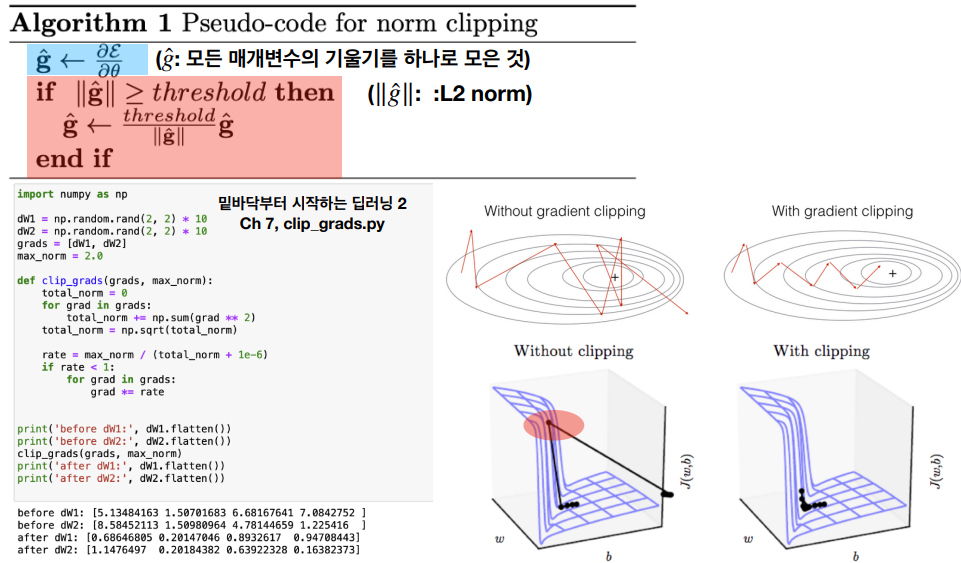
기울기 클리핑 (Gradients Clipping)이란 기울기 값이 일정 크기를 넘어서면 이를 고정된 값으로 제한하여 기울기 폭발을 방지하는 방법을 말한다.
RNN 기울기 폭발 대책 2
LSTM, GRU와 같은 새로운 순환신경망 구조를 사용하여 미분값이 소멸되거나 폭발하지 않는 경로를 만든다.
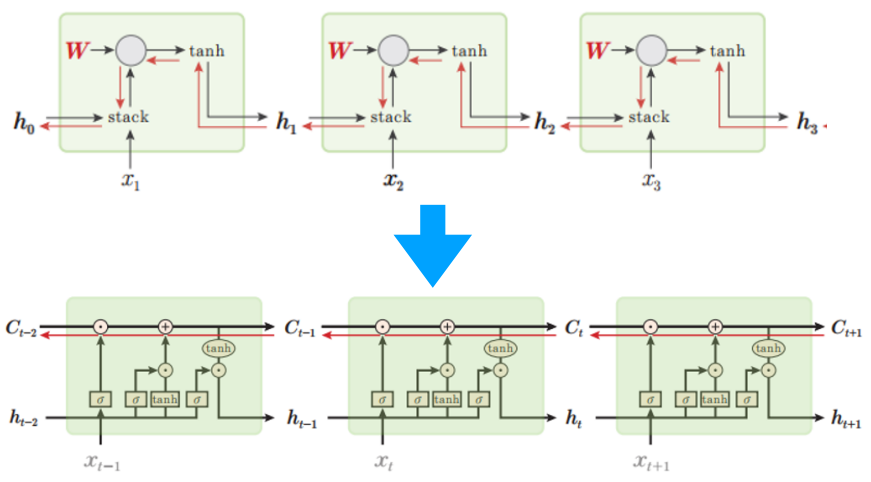
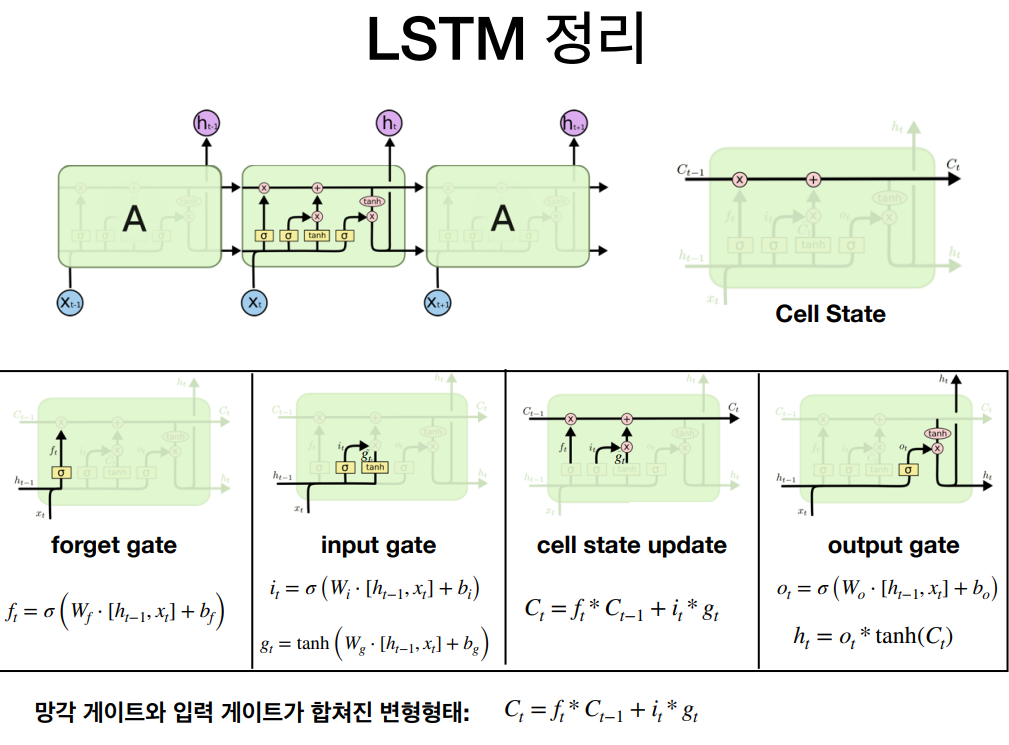
LSTM: Long Short-Term Memory
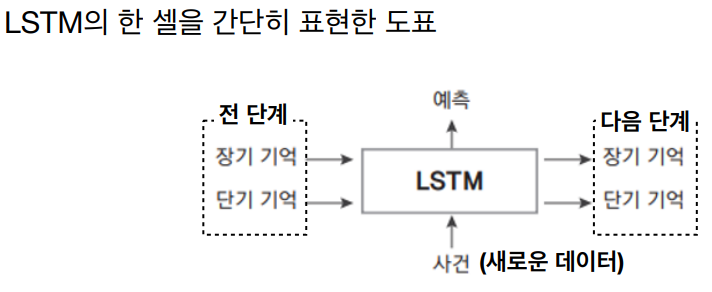
LSTM(Long Short-Term Memory)은 RNN(Recurrent Neural Network)의 한 종류로, 시계열 데이터 처리에 탁월한 성능을 보이는 딥러닝 모델이다. LSTM은 기존 RNN의 단점을 보완하여 장기 의존성 문제를 해결하고자 개발되었다.
LSTM의 주요 특징은 다음과 같다.
셀 상태(Cell State)
LSTM은 셀 상태라는 특별한 메모리 구조를 가지고 있다. 이 셀 상태를 통해 장기 의존성 문제를 해결할 수 있다.
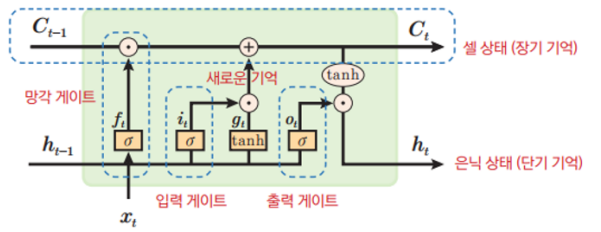
게이트 메커니즘
LSTM은 게이트 메커니즘을 사용한다. 각 게이트는 셀 상태와 현재 입력, 이전 은닉 상태를 이용하여 새로운 셀 상태와 출력을 계산한다. LSTM에는 입력 게이트, 기억 게이트, 망각 게이트, 출력 게이트라는 총 네 종류의 게이트가 있다. 게이트는 기억의 입출력과 처리에 대한 선택을 하며 의미가 있고 자주 사용되는 기억은 기억 게이트에 그렇지 않은 기억은 망각 게이트에 있다.
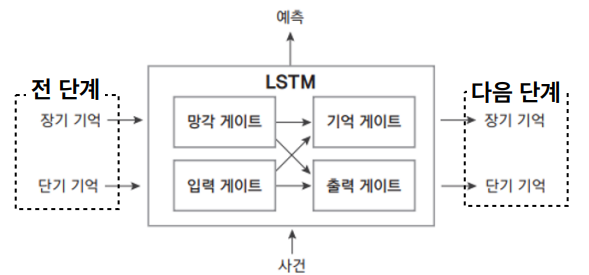
- 망각 게이트: 장기 기억으로 지속할지, 잊을지 판단. 잊혀지는 장기 기억은 망각 게이트를 통과시키지 않음.
- 입력 게이트: 새로운 사건(데이터)로 형성된 기억 중, 장기 기억으로 전환할 기억을 선택
- 기억 게이트: 장기 기억을 새롭게 갱신, 즉 망각 게이트를 통과한 전단계 기억에 입력 게이트를 통과한 새로운 기억을 추가
- 출력 게이트: 갱신된 장기 기억에서 갱신된 단기 기억에 필요한 기억을 선택
기억의 흐름
첫번째 입력(데이터)의 각 단계 반영한다.
- 첫 번째 입력이 입력 게이트를 통해 장기 기억에 반영되어 t=6 예측까지 활용됨
- 단계 4와 단계 6에서 기억 게이트를 통해 새로운 입력(데이터)들과 연합하고, 출력 게이트를 통해 단기 기억으로 선택되어, 예측에 바로 활용됨
- t=7에서는 첫 번째 입력이 불필요하다 판단되어 망각 게이트를 통해 장기 기억에서 지워버림
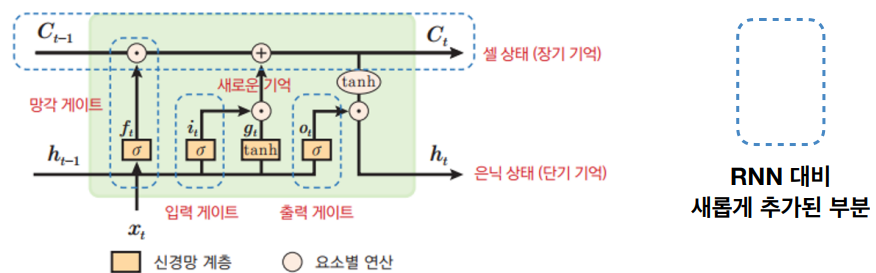

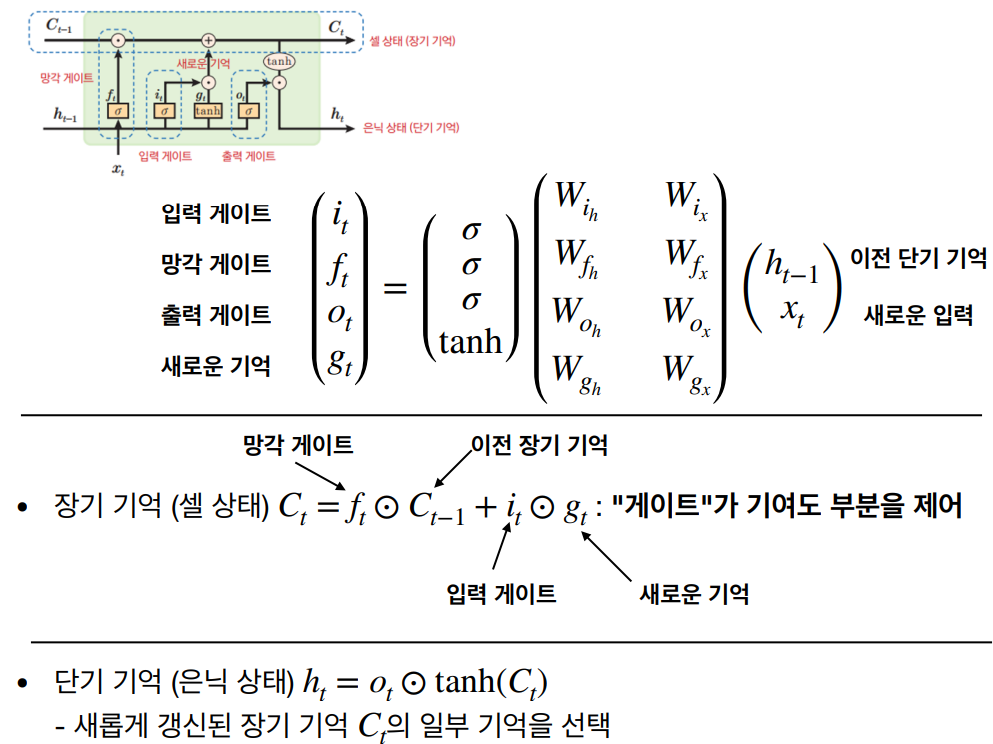
LSTM의 셀구조
- 장기 기억과 단기 기억을 분리하여 관리한다.
- 중요한 기억은 장기 기억으로 유지하고 불필요한 기억은 망각 게이트를 통해 삭제한다.
- 새로 추가된 연결은 가중치 와의 행렬 곱이 없음 (장기 기억)
- 새로운 입력과 기존 기억을 합성하여 장기 기억을 갱신한다.
- 갱신된 장기 기억에서 필요한 부분을 선택하여 단기 기억으로 출력한다.
- Long Memory: 오래 기억되며, 새로운 사건이 발생할 때마다 강화되거나 약화됨
- Short Memory: 최근 사건을 기억하며, 상황이 전환되면 빠르게 잊히며, 같은 사건이 반복되면 단기 기억이 장기 기억으로 전환. (은닉상태)
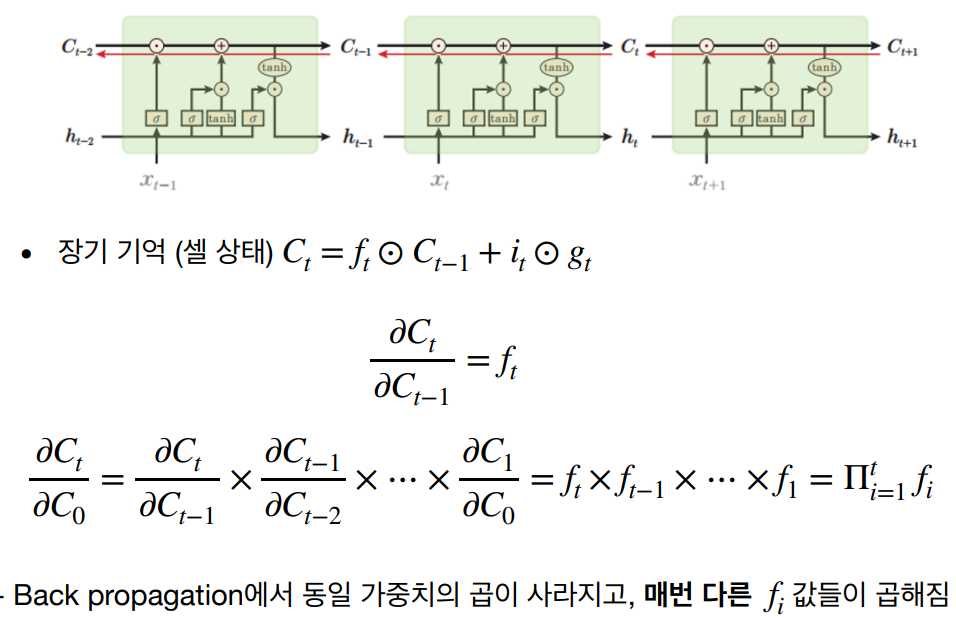
장기 의존성 문제 해결
게이트 메커니즘을 통해 LSTM은 장기 의존성 문제를 효과적으로 해결할 수 있다. 이전 시점의 정보가 현재 시점의 출력에 잘 반영될 수 있도록 한다.
LSTM은 RNN의 한계를 극복하고 장기 의존성 문제를 해결하여 시계열 데이터 처리에 매우 효과적인 모델이다. 다양한 분야에서 LSTM의 활용도가 높아지고 있으며, 지속적인 연구와 발전이 이루어지고 있다.
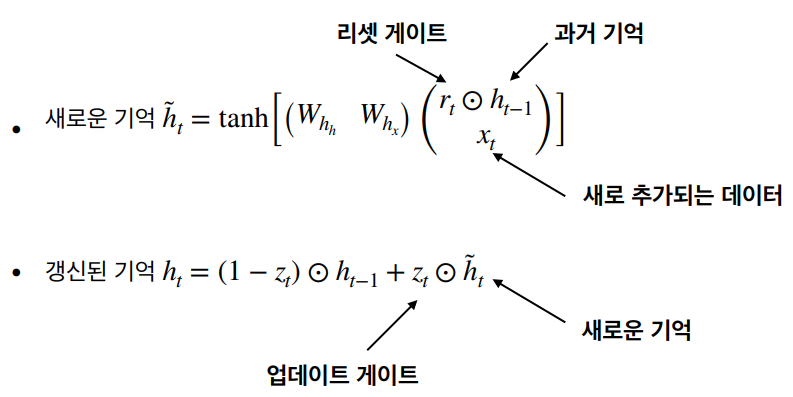
GRU (Gated Recurrent Unit)
GRU는 LSTM의 복잡한 구조를 단순화한 모델이다. 그렇기에 적은 양의 데이터에 적합하다. 셀 상태 Ct를 제거하고, 은닉 상태 ht가 장기 기억과 단기 기억을 모두 담당한다. 리셋 게이트(망각 게이트) rt는 새로운 데이터로 기억을 새롭게 형성하기 위해 장기/단기 기억에서 필요 부분 선택한다. 업데이트 게이트(출력 게이트) zt는 기존 기억과 새로운 기억의 가중치 평균을 통해 기억 갱신한다.
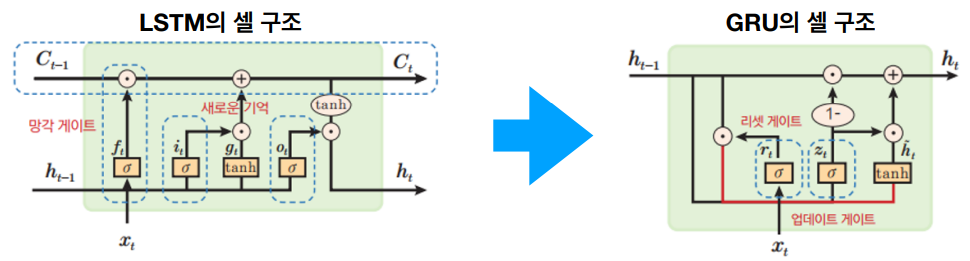
셀 상태 Ct를 없애고, 은닉상태 ht가 장기 기억과 단기 기억을 모두 담당한다. ht의 위 경로는 가중치 W가 없는 장기 기억을 전달한다. ht의 아래 경로는 가중치 W를 통한 단기 기억 전달한다.
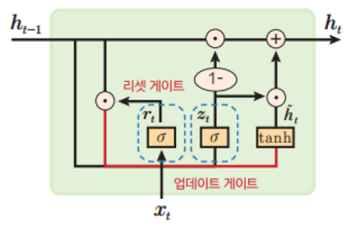
리셋 게이트 rt은 새로운 데이터 ( )로 기억을 새롭게 형성하기 위해, 장기/단기 기억에서 필요 부분 선택한다. 업데이트 게이트 zt는 기존 기억과 새로운 기억의 가중치 평균을 통해 기억 갱신 역할을 한다.
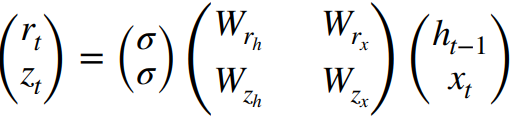
이와 같이 LSTM과 GRU는 RNN의 기울기 문제를 효과적으로 해결하는 모델로, 다양한 순환신경망 문제에서 우수한 성능을 보여주고 있다.
RNN 구현
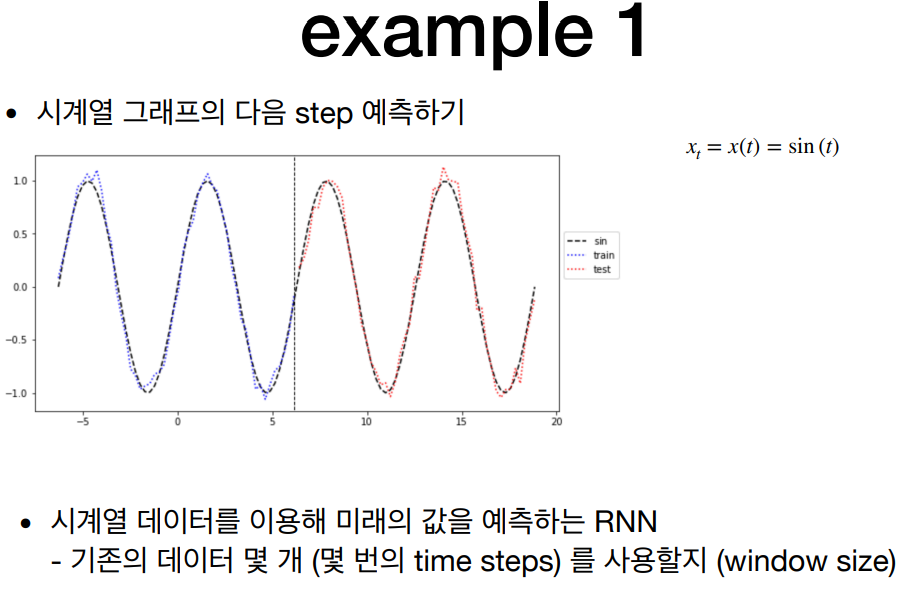
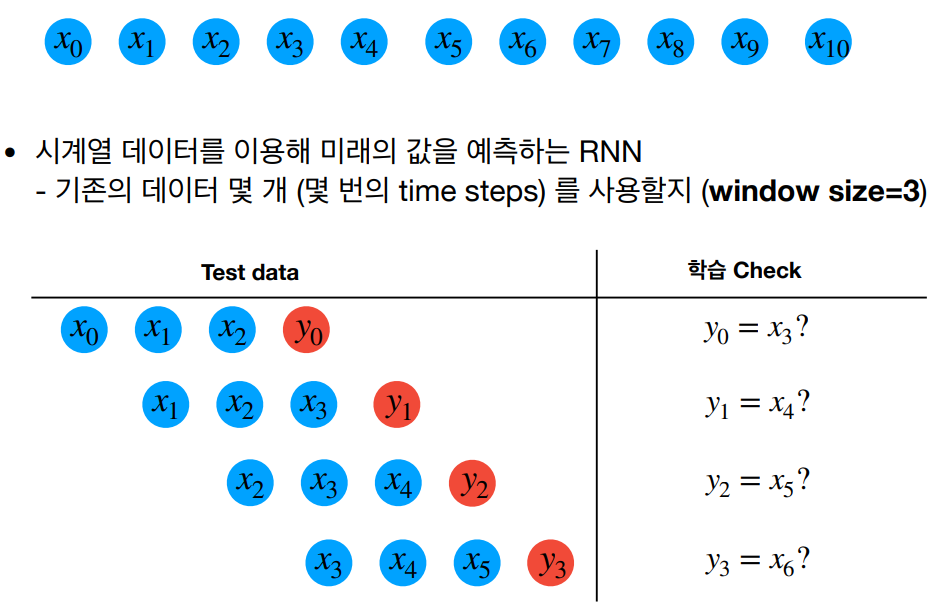
RNN의 기본적인 구현 과정은 다음과 같다.
1. 입력 데이터 준비
- 시계열 데이터를 입력으로 사용한다.
- 입력 데이터를 적절한 크기의 시퀀스로 나누어 RNN에 입력한다.
2. RNN 모델 정의
- 입력 크기, 은닉층 크기, 출력 크기 등 하이퍼 파라미터를 설정한다.
- 입력 가중치, 은닉층 가중치, 출력 가중치 등 학습 가능한 파라미터를 초기화합니다.
3. 순전파 계산
- 현재 시점의 입력과 이전 시점의 은닉 상태를 이용하여 현재 시점의 은닉 상태와 출력을 계산한다.
- 이 과정을 시퀀스의 길이만큼 반복한다.
4. 역전파 계산
- 출력과 실제 타깃 값의 오차를 계산하고, 이를 이용하여 가중치 업데이트를 수행한다.
- 시퀀스의 역방향으로 오차를 전파하며 가중치를 업데이트한다.
5. 모델 학습
- 위 과정을 여러 에폭 동안 반복하여 모델을 학습시킨다.
- 검증 데이터를 이용하여 과적합을 방지한다.
이와 같은 과정을 통해 RNN 모델을 구현할 수 있습니다. 상세한 이해를 위해 RNN 구조와 간략한 코드를 아래를 통해 알 수 있다.


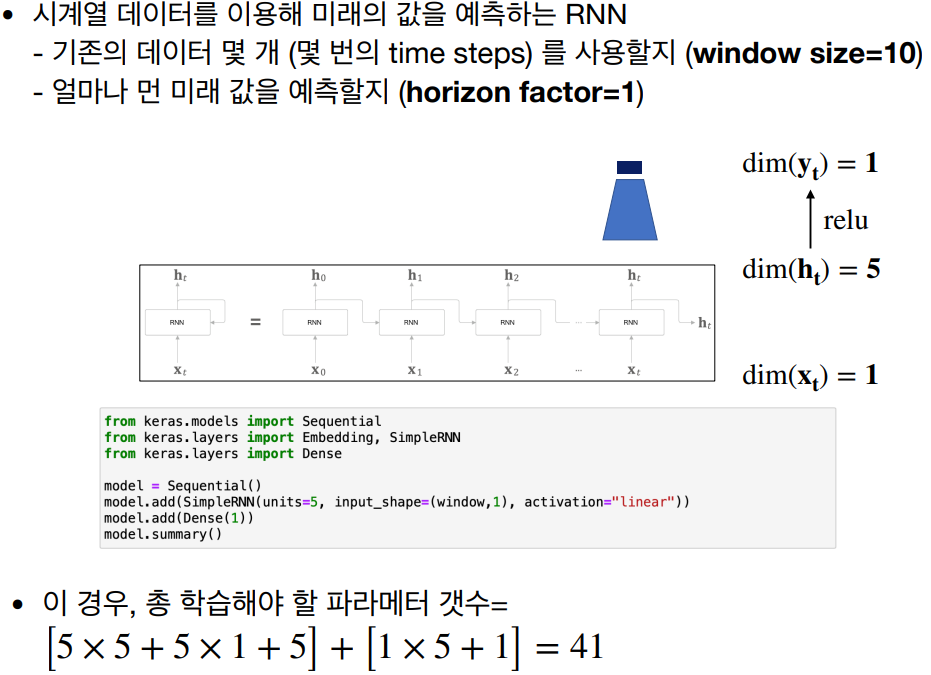
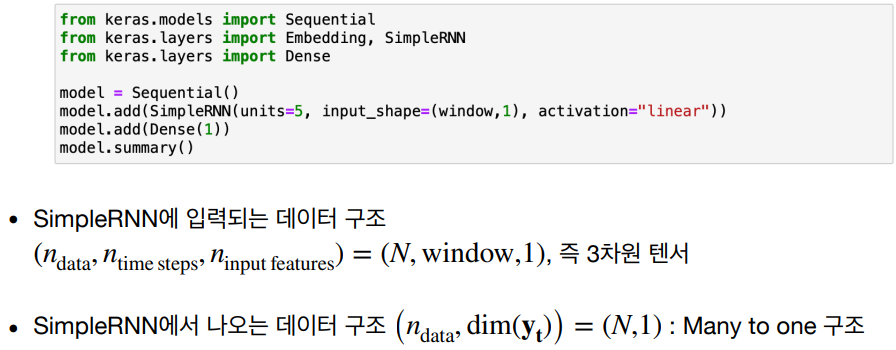
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, SimpleRNN
# 데이터 준비
X_train = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
y_train = np.array([[1, 0], [0, 1]])
# RNN 모델 정의
model = Sequential()
model.add(SimpleRNN(units=4, input_shape=(2, 3)))
model.add(Dense(2, activation='softmax'))
# 모델 컴파일 및 학습
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, batch_size=1)
# 예측
X_test = np.array([[[13, 14, 15], [16, 17, 18]]])
y_pred = model.predict(X_test)
print(y_pred)참고
기계학습 10. Introduction to Artificial Neural Networks(ANN)
서론 이전까지는 기초적인 기계학습 알고리즘을 알아보았고 이제 딥러닝에 대해 간략히 알아보자. 인공 신경망(Artificial Neural Networks, ANN)은 생물학적 뉴런 네트워크에서 영감을 받은 기계 학습
jinger.tistory.com
기계학습 12. Convolutional Neural Networks(CNN)
서론 컨볼루션 신경망(Convolutional neural networks, CNNs)은 뇌의 시각 피질 연구에서 비롯되어 이미지 인식 분야에서 1980년대부터 사용되어 왔다. 지난 몇 년 동안 계산 능력의 증가, 이용 가능한 훈련
jinger.tistory.com
인공지능 5. DNN
서론 딥러닝 네트워크, 특히 DNN(Deep Neural Networks)의 기본 구조와 작동 원리에 대해 알아보자. 데이터가 네트워크를 통해 어떻게 전파되는지부터, 예측과 실제 값 사이의 차이를 어떻게 학습하는
jinger.tistory.com
'컴퓨터공학 > AI' 카테고리의 다른 글
| 비헤이비어트리(Behavior tree) C# 구현 (0) | 2024.07.18 |
|---|---|
| 비헤이비어트리(Behavior tree) 이해 (0) | 2024.07.17 |
| 인공지능 7. 자연어 처리(NLP) (0) | 2024.05.07 |
| 인공지능 6. CNN (0) | 2024.04.25 |
| 인공지능 5. DNN (1) | 2024.04.19 |



댓글