서론
데이터 분석 이전 데이터를 모으거나 받을 때 기본적이며 가장 많이 사용하는 형태인 데이터 프레임(Data Frame)에 대해 알아보자.
데이터 프레임
데이터 프레임은 행과 열로 구성된 표 형태의 데이터를 말한다. 일반적으로 세로로 나열되는 열은 속성을 나타내며 컬럼(Column) 혹은 변수(Variable)라고 불린다. 가로로 나열되는 행은 각 속성의 값을 지닌 정보를 보여주며 Row(로) 혹은 Case(케이스)라고 불린다.
| 이름 | 영어 점수 | 수학 점수 |
| 김지훈 | 90 | 50 |
| 이유진 | 80 | 60 |
| 박동현 | 60 | 100 |
| ... | ... | ... |
| 김민지 | 70 | 20 |
일반적으로 데이터가 크다라는 말은 행 또는 열이 많다라는 말이다. 행이 많다는 것은 분석해야 할 대상이 많은 것으로 컴퓨터의 성능을 높여 문제를 해결하거나 분산 처리 시스템을 구축할 수 있다. 그러나 열이 많다면 각 변수들의 관계를 분석해야 하고 결과의 연관성 등을 알아내야 하기에 단순한 분석 방법으로는 해결하기 힘들다. 그렇기에 고급 분석 방법이 필요하다. 대표적으로 머신러닝이 있다.
변수가 많아지면 적용하는 분석 기술이 달라지기 때문에 분석가는 전보다 많은 노력을 기울여야 한다. 따라서 데이터의 양을 의미하는 행보다 데이터의 다양성을 의미하는 열이 많은 것이 분석 측면에서 더 중요하다.
데이터 분석의 가치는 어떤 현상이 조건에 따라 달라진다는 사실을 발견할 때 생긴다. 이를 가능케 하려면 데이터가 다양한 변수로 구성되어 있어야 한다. 데이터가 아무리 많더라도 다양한 변수를 담고 있지 않으면 변수들 간의 관련성을 분석할 수 없기 때문에 의미 있는 정보를 찾아낼 수 없다. 그렇기에 빅데이터가 아니라 다양한 데이터가 중요하다.
데이터 프레임 만들기
데이터 프레임은 직접 입력하거나 외부에서 가져올 수 있다. 우선 우리는 위 학생들의 수학과 영어 성적을 담은 데이터 프레임을 만들어보자. 데이터 프레임을 만들 때는 "data.frame()"을 이용한다. 데이터 프레임을 구성할 변수를 괄호 안에 쉼표로 나열하면 된다.
english <- c(90, 80, 60, 70) # 영어 점수 변수 생성성
math <- c(50, 60, 100, 20) # 수학 점수 변수 생성성
# 영어, 수학 데이터 프레임 생성해서 df_midterm에 할당
df_midterm <- data.frame(english, math)
df_midterm
## english math
## 1 90 50
## 2 80 60
## 3 60 100
## 4 70 20
# 반 데이터 추가하여 추가된 데이터 프레임 만들기
class <- c(1, 1, 2, 2)
df_midterm <-data.frame(english,math,class)
df_midterm
## english math class
## 1 90 50 1
## 2 80 60 1
## 3 60 100 2
## 4 70 20 2위 예시는 여러 변수를 각각 만든 후 합치는 형태로 데이터 프레임을 만들었다. 이번에는 한 번에 만드는 방법을 알아보자.
df_midterm <- data.frame(english = c(90, 80, 60, 70),
math = c(50, 60, 100, 20),
class = c(1, 1, 2, 2))
df_midterm
## english math class
## 1 90 50 1
## 2 80 60 1
## 3 60 100 2
## 4 70 20 2완성된 데이터 프레임을 통해 분석해 보자. "mean()"함수는 평균을 구하는 함수이다. "df_midterm$english"는 "df_midterm 안에 있는 english 변수"를 의미한다. 즉, "$"(달러 기호)는 데이터 프레임 안에 있는 변수를 지정할 때 사용한다.
mean(df_midterm$english)
## [1] 75
mean(df_midterm$math)
## [1] 57.5외부 데이터 이용하기
"Do It! 쉽게 배우는 R 데이터 분석"의 깃허브에서 실습에 사용할 execel_exam.xlsx파일을 다운로드하거나 이미 보유한 엑셀 파일을 이용해도 된다. 예시 엑셀을 살펴보면 변수는 학생 id, class, math, english, science로 구성되어 있다. 즉, 학생의 번호와 반 정보와 각 학생의 수학, 영어, 과학 시험 점수가 기록되어 있다. 추가적으로 학생 수는 총 20명이라는 사실도 알 수 있다.

위 엑셀 파일을 R 스튜디오의 프로젝트 파일에 넣어두면 손쉽게 불러올 수 있다. 또한 엑셀 파일을 불러오려면 엑셀 파일을 불러오는 기능을 제공하는 패키지를 이용해야 한다. "readxl"패키지를 설치하고 로드하여 준비하자.

install.packages("readxl")
library(readxl)
만약 같은 폴더 내에 있어도 작동이 잘 안 되는 경우 위 예시처럼 엑셀 파일의 위치를 직접 지정해서 불러올 수 있다.
엑셀 파일 첫 번째 행이 변수명이 아니라면?
실습에 사용한 엑셀 파일은 첫 번째 행에 변수명이 입력되어 있다. "read_excel()"는 기본적으로 엑셀 파일의 첫 번째 행을 변수명으로 인식해 불러온다. 변수명 없이 첫 번째 행부터 바로 데이터가 시작되는 경우, 첫 번째 행의 데이터가 변수명으로 지정되면서 유실되는 문제가 발생한다. 이럴 때 "read_excel()"의 파라미터 "col_names = F"를 설정하면 첫 번째 행을 변수명이 아닌 데이터로 인식해 불러오고, 변수명은 '...숫자'로 자동 지정된다.
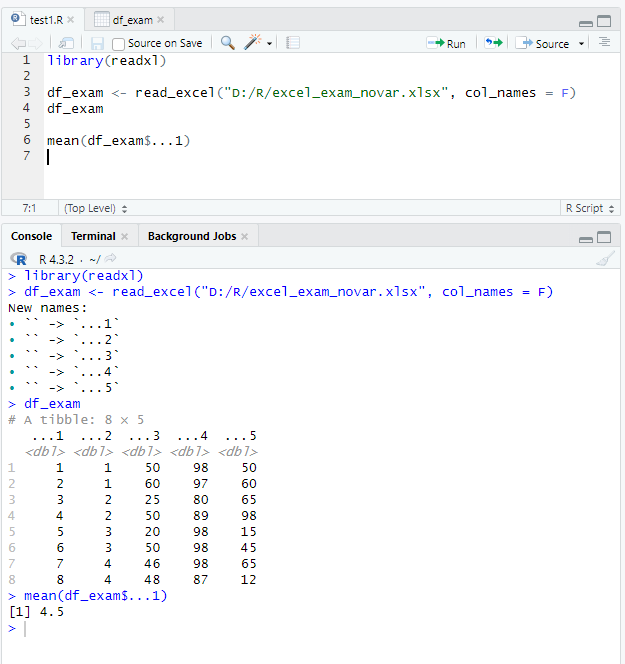
R에는 참(True)과 거짓(False) 중 하나로 구성되는 논리형 벡터(Logical Vectors)라는 변수 타입이 있다. 논리형 벡터는 어떤 값이 참인지 거짓인지 나타낸다. 논리형 벡터는 반드시 대문자 TRUE 혹은 FALSE로 입력하거나 앞글자만 따서 T 또는 F를 입력해야 한다.
엑셀 파일에 시트가 여러 개 있다면?
여러 개의 시트로 구성된 엑셀 파일을 불러올 경우 "sheet" 파라미터를 이용해 몇 번째 시트의 데이터를 불러올지 지정할 수 있다.
df_exam_sheet <- read_excel("excel_exam_sheet.xlsx", sheet = 3)CSV 파일
CSV(Comma-separated Values) 파일은 엑셀뿐 아니라 SAS, SPSS 등 데이터를 다루는 대부분의 프로그램에서 읽고 쓰기가 가능한 범용 데이터 파일이다. csv파일은 쉼표로 구분되어 있는 형태이다. 다양한 프로그램에서 지원하고 엑셀 파일에 비해 용량이 작기 때문에 데이터를 주고받을 때는 csv 파일을 더 자주 이용한다.

파일 불러오기
이 예시 또한 마찬가지로 깃허브나 본인이 가진 데이터로 사용해도 된다. 불러오는 방법은 위 엑셀 방식과 동일하다.
df_csv_exam <- read.csv("csv_ecam.csv")
df_csv_exam
## id class math english science
## 1 1 1 50 98 50
## 2 2 1 60 97 60
## 3 3 1 45 86 78
## 4 4 1 30 98 58
## 5 5 2 25 80 65
## 6 6 2 50 89 98
...파일 저장하기
데이터 프레임을 csv 파일로 저장하면 R 외에도 데이터를 다루는 대부분의 프로그램에서 불러올 수 있다. R 내장 함수 "write.csv()" 함수를 이용해 데이터 프레임을 csv 파일로 저장한다. 괄호 안에 저장할 데이터 프레임명을 지정하고, file 파라미터에 파일명을 지정하면 된다. 저장한 파일은 프로젝트 폴더에 생성된다.
df_midterm <- data.frame(english = c(90, 80, 60, 70),
math = c(50, 60, 100, 20),
class= c(1, 1, 2, 2))
write.csv(df_midterm, file = "df_midterm.csv")RDS 파일
RDS 파일은 R 전용 데이터 파일이다. R 전용 파일이므로 다른 파일들에 비해 R에서 읽고 쓰는 속도가 빠르고 용량이 작다는 장점이 있다. 일반적으로 R에서 분석 작업을 할 때는 RDS 파일을 이용하고, R을 사용하지 않는 사람과 파일을 주고받을 때는 CSV 파일을 이용한다.
데이터 프레임을 RDS 파일로 저장할 때에는 "saveRDS()"를 이용해 데이터 프레임을 ".rds" 파일로 저장한다. 불러올 때는 "readRDS()"를 이용한다.
saveRDS(df_midterm, file="df_midterm.rds") # 앞서 만든 df_midterm을 RDS 파일로 저장
rm(df_midterm) # 앞서 만든 df_midterm을 삭제
df_midterm # 에러 발생
df_midterm <- readRDS("df_midterm.rds")
df_midterm"rm()"을 이용하면 앞서 선언한 데이터를 삭제할 수 있다.
주섬주섬
정리
# 1.변수 만들기, 데이터 프레임 만들기
english <- c(90, 80, 60, 70) # 영어 점수 변수 생성
math <- c(50, 60, 100, 20) # 수학 점수 변수 생성
data.frame(english, math) # 데이터 프레임 생성
# 2.외부 데이터 이용하기
# 엑셀 파일
library(readxl) # readxl 패키지 로드
df_exam <- read_excel("excel_exam.xlsx") # 엑셀 파일 불러오기
# CSV 파일
df_csv_exam <-read.csv("csv_exam.csv") # csv 파일 불러오기
write.csv(df_midterm, file = "df_midterm.csv") # csv 파일로 저장하기
# RDA 파일
load("df_midterm.rda") # rda 파일 불러오기
save(df_midterm, file="df_midterm.rda") # rda 파일로 저장하기참고
GitHub - youngwoos/Doit_R: <Do it! 쉽게 배우는 R 데이터 분석> 저장소
<Do it! 쉽게 배우는 R 데이터 분석> 저장소. Contribute to youngwoos/Doit_R development by creating an account on GitHub.
github.com
'프로그래밍 언어 > R' 카테고리의 다른 글
| R 6. 데이터 정제하기 (0) | 2024.01.30 |
|---|---|
| R 5. 데이터 가공하기 (0) | 2024.01.29 |
| R 4. 데이터 파악하기 (2) | 2024.01.27 |
| R 2. 데이터 분석 이전 기본 개념 (2) | 2024.01.25 |
| R 1. R 들어가기 앞서 (0) | 2024.01.23 |




댓글