관계형 데이터베이스

관계형 데이터베이스(RDB, Relational Database)는 데이터를 행(Row)과 열(Column)로 이루어진 테이블(Table) 구조로 저장하고, 테이블 간의 관계(Relation)를 통해 데이터를 연결하는 방식의 데이터베이스이다. 대표적으로 RDBMS Oracle, MySQL / MariaDB, SQLite 등이 여기에 속한다. SQL(Structured Query Language)은 관계형 데이터베이스에서 테이블를 만들고, 데이터를 다루고, 사용자 권한과 트랜잭션까지 다루기 위해 사용하는 언어이다.
테이블(Table)
- 하나의 주제(예: 고객, 주문, 상품 등)를 표현하는 구조
- 데이터는 행(Row), 속성은 열(Column)
- 테이블은 스프레드시트처럼 생겼지만, 명확한 제약조건과 관계 구조를 가짐
튜플(Tuple) = 행(Row)
- 하나의 레코드 (예: 한 명의 고객, 한 건의 주문)
속성(Attribute) = 열(Column)
- 데이터의 항목 (예: 고객명, 이메일, 주문일 등)
기본 키(Primary Key)
- 각 행을 유일하게 식별하는 속성
- 예: 고객 테이블에서 고객ID, 주문 테이블에서 주문번호
외래 키(Foreign Key)
- 다른 테이블의 기본키를 참조하는 속성
- 테이블 간 관계를 표현하는 도구
- 예: 주문 테이블의 고객ID가 고객 테이블의 고객ID를 참조
관계(Relation)
- 테이블 간의 연관성
- 1:1, 1:N, N:M 등
- SQL에서 JOIN으로 표현
SELECT 문
SELECT는 저장되어 있는 데이터를 조회하고자 할 때 사용하는 명령어이다. 기본구조는 다음과 같다. 여기서 칼럼명 대신에 *(별표, asterisk)를 사용하면 전체 칼럼이 조회되며 조회되는 칼럼의 순서는 테이블의 칼럼 순서와 동일하다. 그리고 별도의 WHERE절이 없으면 테이블의 전체 행(ROW)이 조회된다.
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명
WHERE 조건
ORDER BY 정렬기준;SELECT name, age FROM users WHERE age > 30 ORDER BY age;산술 연산자
수학에서 사용하는 사칙연산의 기능을 가진 연산자이다. 괄호, 곱하기, 나누기, 더하기, 빼기가 존재하며 계산 순서는 동일하다.
- +: 더하기
- -: 빼기
- *: 곱하기
- /: 나누기
- %: 나머지 (RDBMS에 따라 지원 여부 다름)
그 외에 합성연산자라 하여 문자와 문자를 연결(concatenate)할 때 사용하는 연산자가 있다. 이는 DBMS마다 조금씩 다르며, 문자열 연결 연산자라고도 불린다. 이 때 NULL이 섞이면 결과도 NULL이 되는 DBMS도 있어 주의해야 한다.
- Oracle: '
- MySQL: CONCAT() 함수
- PostgreSQL: '
- SQL Server: +
함수
함수는 입력값(인수)을 받아서 하나의 결과값을 반환하는 연산 도구이다.
문자 함수
| 함수 | 사용법 | 인수 | 설명 | 반환 |
| LOWER | LOWER('ABC') | 문자열 | 소문자로 변환 | 'abc' |
| UPPER | UPPER('abc') | 문자열 | 대문자로 변환 | 'ABC' |
| LTRIM | LTRIM(' hello') | 문자열, (선택: 제거할 문자) | 왼쪽 공백 또는 문자 제거 | 'hello' |
| RTRIM | RTRIM('hello ') | 문자열, (선택: 제거할 문자) | 오른쪽 공백 또는 문자 제거 | 'hello' |
| TRIM | TRIM(' a ') | 문자열, (선택: 제거할 문자) | 양쪽 공백 또는 문자 제거 | 'a' |
| SUBSTR | SUBSTR('abcdef', 2, 3) | 문자열, 시작위치, 길이 | 부분 문자열 추출 | 'bcd' |
| LENGTH | LENGTH('hello') | 문자열 | 길이 반환 | 5 |
| REPLACE | REPLACE('hello', 'l', '*') | 문자열, 찾을값, 바꿀값 | 문자열 치환 | 'he**o' |
| LPAD | LPAD('7', 3, '0') | 문자열, 전체길이, 채울문자 | 왼쪽 패딩 | '007' |
숫자 함수
| 함수 | 사용법 | 인수 | 설명 | 반환 |
| ABS | ABS(-10) | 숫자 | 절댓값 | 10 |
| SIGN | SIGN(-5) | 숫자 | 부호 판단 | -1 |
| TRUNC | TRUNC(12.345, 1) | 숫자, (선택: 자를 자리수) | 자리 내림 | 12.3 |
| CEIL | CEIL(3.14) | 숫자 | 올림 | 4 |
| FLOOR | FLOOR(3.99) | 숫자 | 내림 | 3 |
| MOD | MOD(10, 3) | 피제수, 제수 | 나머지 | 1 |
날짜 함수
| 함수 | 사용법 | 인수 | 설명 | 반환 |
| SYSDATE | SYSDATE | 없음 | 현재 날짜/시간 | 2025-05-13 (예시) |
| EXTRACT | EXTRACT(YEAR FROM SYSDATE) | 날짜, 구성요소 | 날짜에서 연/월/일 추출 | 2025 |
| ADD_MONTHS | ADD_MONTHS(SYSDATE, 3) | 날짜, 개월수 | 개월 수 더함 | +3개월 후 날짜 |
변환 함수
변환 함수는 데이터의 형식(타입)을 바꾸는 함수이며, 두 가지 방법으로 나눌 수 있다. 개발자가 직접 함수나 구문을 써서 형식을 바꾸는 명시적 형변환(explicit type casting)과 SQL 문장 안에서 DBMS가 자동으로 알아서 형을 바꾸는 암시적 형변환(implicit type casting)이 있다.
| 함수 | 사용법 | 인수 | 설명 | 반환 |
| TO_NUMBER | TO_NUMBER('1234') | 문자열 | 숫자로 변환 | 1234 |
| TO_CHAR | TO_CHAR(SYSDATE, 'YYYY-MM-DD') | 날짜/숫자, 포맷 | 문자열로 변환 | '2025-05-13' |
| TO_DATE | TO_DATE('2025-05-13', 'YYYY-MM-DD') | 문자열, 포맷 | 날짜로 변환 | 날짜형 |
NULL 관련 함수
| 함수 | 사용법 | 인수 | 설명 | 반환 |
| NVL | NVL(NULL, '기본값') | 검사값, 대체값 | NULL이면 대체값 | '기본값' |
| NULLIF | NULLIF(100, 100) | 값1, 값2 | 두 값이 같으면 NULL | NULL |
| COALESCE | COALESCE(NULL, NULL, '값') | 여러 값 | NULL이 아닌 첫 값 | '값' |
| NVL2 | NVL2(col, 'A', 'B') | 조건값, NULL 아닐 때, NULL일 때 | IF문과 유사 | 'A' or 'B' |
| CASE | CASE WHEN x=1 THEN 'A' ELSE 'B' END | 조건식 | 다중 조건 처리 | 'A', 'B' 등 |
WHERE 절
INSERT를 제외한 DML문을 수행할 때 원하는 데이터만 골라 수행할 수 있도록 해주는 구문이다. 여기서 연산자(operator)는 SQL에서 값과 값을 비교하거나 조작할 때 사용하는 기호나 키워드이다.
SELECT * FROM 테이블명
WHERE 조건식;비교 연산자
- =: 같다
- != 또는 <>: 같지 않다
- >: 크다 (초과)
- <: 작다 (미만)
- >=: 크거나 같다 (이상)
- <=: 작거나 같다 (이하)
SQL 연산자
- BETWEEN A AND B: A 이상 B 이하의 범위
- IN (값1, 값2, ...): 목록 중 하나와 일치
- LIKE '패턴': 패턴과 일치 (%는 여러 글자, _는 한 글자)
- IS NULL: 값이 NULL인지 확인
- IS NOT NULL: NULL이 아닌 값 확인
논리 연산자
- AND: 모든 조건이 참일 때
- OR: 하나라도 조건이 참이면 참
부정 연산자
- NOT: 조건을 부정함
- NOT BETWEEN A AND B: A 미만 또는 B 초과
- NOT IN (...): 목록에 포함되지 않음
- NOT LIKE '패턴': 패턴과 일치하지 않음
GROUP BY 절
특정 컬럼 기준으로 데이터를 묶고, 그 안에서 집계함수를 적용할 때 사용한다. 단순 SELECT와 달리, 행(row)들을 그룹 단위로 요약 처리한다.
SELECT 부서, COUNT(*)
FROM 직원
GROUP BY 부서;집계함수
| 함수 | 사용법 | 인수 | 설명 | 반환 |
| COUNT | COUNT(*) | 컬럼명 또는 * | 행의 개수 계산 | 숫자 (정수) |
| SUM | SUM(salary) | 숫자형 컬럼 | 합계 계산 | 숫자 |
| AVG | AVG(score) | 숫자형 컬럼 | 평균 계산 | 숫자 (소수 가능) |
| MAX | MAX(hire_date) | 숫자형 또는 날짜형 컬럼 | 최댓값 반환 | 컬럼 타입과 동일 |
| MIN | MIN(price) | 숫자형 또는 날짜형 컬럼 | 최솟값 반환 | 컬럼 타입과 동일 |
HAVING 절
WHERE은 행(row)을 기준 필터링했고, HAVING은 그룹 기준 필터링하였다면, GROUP BY로 묶은 결과에 대해 조건을 줄 때 사용한다.
SELECT 부서, COUNT(*) AS 인원수
FROM 직원
GROUP BY 부서
HAVING COUNT(*) >= 5;ORDER BY 절
ORDER BY는 결과를 정렬할 때 사용하는 절이다. SELECT 절 뒤에서 사용하며 숫자, 문자열, 날짜 모두 정렬 가능하다. 결과 행들을 오름차순(ASC) 또는 내림차순(DESC)으로 정렬한다. 오름차순의 경우 생략이 가능하다.
논리적 수행 순서
SQL을 사용하는 순서와 달리 내부적으로 처리하는 순서(논리적 수행 순서)가 다르다.
| 구절 | 배치 순서 | 논리적 수행 순서 |
| SELECT | 1 | 5 |
| FROM | 2 | 1 |
| WHERE | 3 | 2 |
| GROUP BY | 4 | 3 |
| HAVING | 5 | 4 |
| ORDER BY | 6 | 6 |
JOIN
JOIN은 두 개 이상의 테이블을 연결해서 하나의 결과 집합으로 만드는 것이다. JOIN은 FROM절에서 사용한다.
SELECT *
FROM 고객 c
JOIN 주문 o ON c.고객ID = o.고객ID;EQUI JOIN (등가 조인)
등가 조인은 두 테이블의 컬럼 값이 같은 경우만 연결할 수 있다. = 연산자를 사용한다. 아래 예시에서 e.부서ID = d.부서ID가 공통키(등가조건)로 연결된다. INNER JOIN(내부 조인)과 거의 같은 개념으로 쓰인다.
SELECT e.이름, d.부서명
FROM 사원 e
JOIN 부서 d ON e.부서ID = d.부서ID;Non-EQUI JOIN (비등가 조인)
=, 즉 정확히 같은 값이 아니라 다른 비교 연산자 (<, >, BETWEEN 등)를 쓰는 조인이다. 주로 구간별 조건 매핑 등에 사용된다.
SELECT 급여, 등급
FROM 급여표 s
JOIN 등급표 g ON s.급여 BETWEEN g.하한 AND g.상한;3개 이상 TABLE JOIN
JOIN은 여러 테이블을 계속 연결할 수 있다. 두 개씩 순차적으로 연결하고 괄호 없이 사용해도 된다.
SELECT o.주문ID, c.이름, p.상품명
FROM 주문 o
JOIN 고객 c ON o.고객ID = c.고객ID
JOIN 상품 p ON o.상품ID = p.상품ID;OUTER JOIN (외부 조인)
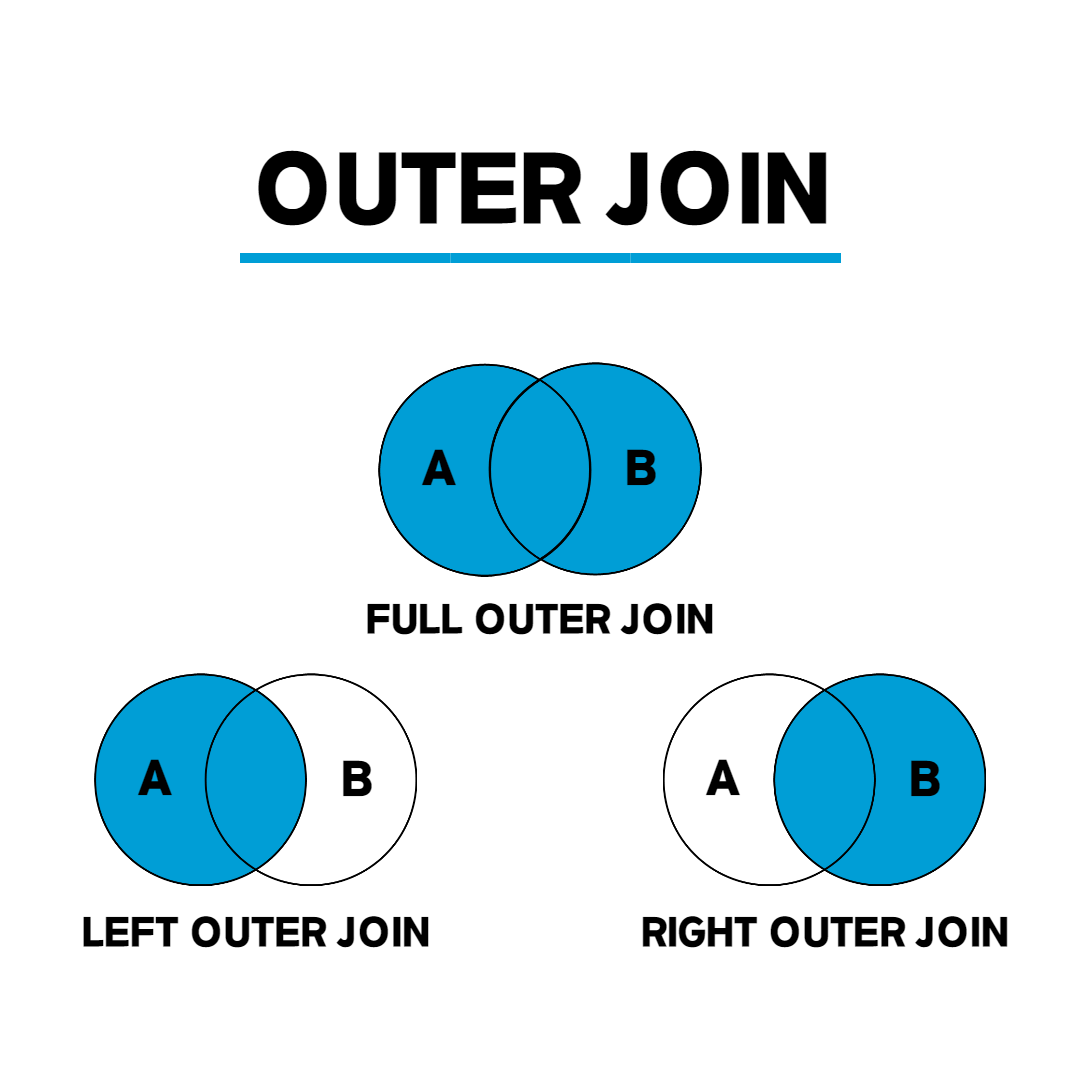
조건이 맞지 않아도 한쪽 테이블의 데이터를 유지하는 조인이다. 한쪽에 데이터가 없어도 결과에 포함된다. (NULL로 채움)
- LEFT OUTER JOIN: 왼쪽 테이블은 모두 표시, 오른쪽은 조건 맞는 것만
- RIGHT OUTER JOIN: 오른쪽 테이블은 모두 표시, 왼쪽은 조건 맞는 것만
- FULL OUTER JOIN: 양쪽 테이블 모두 표시 (PostgreSQL, Oracle 등에서 지원)
STANDARD JOIN
기존의 Oracle-style 조인 (WHERE에서 A.emp_id = B.emp_id) 대신, SQL 표준 문법인 JOIN ~ ON 형식을 사용하는 조인 방식이다. 가독성 좋고, JOIN 조건을 명확히 분리할 수 있어서 실무에서 권장된다.
INNER JOIN (내부 조인)
가장 기본적인 조인으로 양쪽 테이블에 모두 존재하는 일치 데이터만 결과로 반환하는 조인이다. JOIN 또는 INNER JOIN은 동일 의미한다.
SELECT e.name, d.name
FROM employee e
INNER JOIN department d ON e.dept_id = d.dept_id;
OUTER JOIN (외부 조인)
조건이 맞지 않아도 한쪽 테이블의 데이터를 보존하는 조인이다. 조건이 없는 쪽은 NULL로 채워서 출력한다.
SELECT e.name, d.name
FROM employee e
LEFT OUTER JOIN department d ON e.dept_id = d.dept_id;
NATURAL JOIN (자연 조인)
공통된 컬럼 이름이 있을 경우, 자동으로 조건 생성해서 조인이다. ON절 없이 조인할 수 있지만 의도치 않은 칼럼을 조인할 수 있으므로 선호하지 않는다.
SELECT *
FROM employee
NATURAL JOIN department;
CROSS JOIN (교차 조인)
모든 행 조합을 반환 (곱집합) 조인이다. 조건 없이 조인되어 N × M개의 행 생성된다. 그렇기에 필터 조건이 없으면 폭발적인 결과량에 주의해야한다. 예를 들어 직원이 10명, 부서가 3개면 결과는 30행이 생성된다.
SELECT e.name, d.name
FROM employee e
CROSS JOIN department d;
'프로그래밍 언어 > SQL' 카테고리의 다른 글
| SQL 관리 구문 (1) | 2025.05.24 |
|---|---|
| SQL 활용 (0) | 2025.05.24 |
| 데이터 모델과 SQL (2) | 2025.05.24 |
| 데이터 모델링의 이해 (3) | 2025.05.24 |




댓글