서론
여러 개의 예측기(분류기 또는 회귀기와 같은)의 예측을 종합하면 종종 최상의 개별 예측기보다 더 나은 예측을 얻을 수 있다. 예측기들의 그룹은 앙상블이라고 하며, 이 기술은 앙상블 학습(Ensemble Learning)이라고 불리며, 앙상블 학습 알고리즘은 앙상블 방법(Ensemble method)이라고 한다. 예를 들어, 다른 훈련 세트의 무작위 하위 집합으로 나누어 각각 결정 트리 분류기를 훈련시킬 수 있다. 예측을 수행하기 위해 모든 개별 트리의 예측을 얻은 다음 가장 많은 투표를 받은 클래스를 예측한다. 이러한 결정 트리의 앙상블은 랜덤 포레스트(Random Forests)라고 불리며, 그 간단함에도 불구하고 현재 가장 강력한 머신 러닝 알고리즘 중 하나이다.
Voting Classifiers

# 세 가지 분류기로 구성된 Scikit-Learn에서 투표 분류기를 생성하고 훈련
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf = LogisticRegression()
rnd_clf = RandomForestClassifier()
svm_clf = SVC()
voting_clf = VotingClassifier(
estimators = [('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting = 'hard')
voting_clf.fit(X_train, y_train)
# 테스트 세트에 대한 각 분류기의 정확도
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_train)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
# LogisticRegression 0.864
# RandomForestClassifier 0.896
# SVC 0.888
# VotingClassifier 0.904Voting Classifiers를 생성하고 훈련시켜 보자. 로지스틱 회귀, 랜덤 포레스트, SVC와 같이 서로 다른 알고리즘을 사용하여 다양한 분류기 세 개로 구성된 투표 분류기를 Scikit-Learn에서 만들고 훈련시킬 수 있다. 각 분류기의 테스트 세트에서의 정확도를 확인하고, 만약 모든 분류기가 클래스 확률을 추정할 수 있는 경우(즉, 모든 분류기가 predict_proba() 메서드를 가지고 있는 경우), Scikit-Learn에게 모든 개별 분류기에 걸쳐 평균화된 가장 높은 클래스 확률을 갖는 클래스를 예측하도록 지시할 수 있다. 이를 soft voting라고 합니다. voting="hard"를 voting="soft"로 바꾸고 모든 분류기가 클래스 확률을 추정할 수 있도록 확인하는 것이 필요하다. SVC 클래스는 기본적으로 이것이 아니기 때문에 probability 하이퍼파라미터를 True로 설정해야 한다.(이렇게 하면 SVC 클래스가 교차 검증을 사용하여 클래스 확률을 추정하므로 훈련 시간이 느려지며 predict_proba() 메서드가 추가된다)
Bagging and Pasting
모든 예측기에 동일한 훈련 알고리즘을 사용하여 훈련시키고, 이들을 훈련 세트의 서로 다른 무작위 하위 집합에 훈련시키는 방법도 존재한다. 복원 추출을 사용할 때 이 방법은 배깅(bootstrap aggregating의 약자)이라고 하며, 복원 추출을 사용하지 않을 때는 페이스팅(pasting)이라고 한다. 다시 말해, 배깅과 페이스팅 모두 훈련 인스턴스를 여러 번 예측기 간에 샘플링할 수 있게 하지만, 배깅은 동일한 예측기에 대해 여러 번 샘플링할 수 있도록 한다. 예측기들은 모두 병렬로 훈련할 수 있으며, 서로 다른 CPU 코어나 서버를 통해 이루어진다. 이것이 배깅과 페이스팅이 인기 있는 이유 중 하나이다. 즉, 이들은 확장성이 매우 뛰어나다.
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators = 500,
max_samples = 100, bootstrap = True, n_jobs = -1)
bag_clf.fit(X_train, y_train)
y_pred = bad_clf.predict(X_test)
모든 예측기가 훈련된 후, 앙상블은 모든 예측기의 예측을 단순히 집계하여 새로운 인스턴스에 대한 예측을 수행할 수 있다. 집계 함수는 일반적으로 분류의 경우 통계적인 모드(가장 빈번한 예측, 마치 하드 투표 분류기와 유사)를, 회귀의 경우 평균을 사용한다. 각각의 개별 예측기는 원래 훈련 세트에 대해 훈련된 경우보다 더 높은 편향을 가지지만, 집계는 편향과 분산을 모두 감소시킨다. 일반적으로 앙상블은 유사한 편향을 가지지만 원래 훈련 세트에 대해 훈련된 단일 예측기보다는 낮은 분산을 가진다. 부트스트래핑은 각 예측기가 훈련되는 하위 집합에서 약간 더 많은 다양성을 가져오므로, 배깅은 페이스팅보다 약간 더 높은 편향을 가지게 된다.
Out-of-Bag Evaluation
배깅을 사용할 경우 각 예측기에 대해 일부 인스턴스는 여러 번 샘플링되고, 다른 인스턴스는 전혀 샘플링되지 않을 수 있다. 기본적으로 BaggingClassifier는 m개의 훈련 인스턴스를 복원 샘플링(bootstrap=True)하는데, 여기서 m은 훈련 세트의 크기이다. 따라서 평균적으로 각 예측기에 대해 전체 훈련 인스턴스의 약 63%만 샘플링된다. 샘플링되지 않은 나머지 37%의 훈련 인스턴스는 out-of-bag (oob) 인스턴스라고 한다. 이들은 모든 예측기에 대해 동일하지 않음에 유의해야 한다.
훈련 중 예측기가 oob 인스턴스를 볼 수 없기 때문에 별도의 검증 세트가 필요하지 않고 이러한 인스턴스에 대해 평가할 수 있다. Scikit-Learn에서는 BaggingClassifier를 만들 때 oob_score=True로 설정하여 자동 oob 평가를 요청할 수 있다. 이 oob 평가에 따르면 해당 BaggingClassifier는 테스트 세트에서 약 90.1%의 정확도를 달성할 것으로 예상된다. 이를 확인해 보자.
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators = 500,
bootstrap = True, n_jobs = -1, oob_score = True)
bag_clf.fit(X_train, y_train)
bag_clf.oob_score_ # 0.90133333332
from sklearn.metrics import accuracy_score
y_pred = bag_clf.predict(X_test)
accracy_score(y_test, y_pred) # 0.9120000000003Random Patches and Random Subspaces
BaggedClassifier 클래스는 features 샘플링도 지원한다. 샘플링은 max_features 및 bootstrap_features라는 두 가지 하이퍼 매개변수로 제어된다. max_samples 및 bootstrap과 동일한 방식으로 작동하지만 인스턴스 샘플링 대신 기능 샘플링을 위한 것이다. 따라서 각 예측기는 입력 특성의 무작위 하위 집합에 대해 훈련된다. 이 기술은 고차원 입력(예: 이미지)을 처리할 때 특히 유용하다. 훈련 인스턴스와 기능을 모두 샘플링하는 것을 Random Patches 방법이라고 한다. 모든 훈련 인스턴스를 유지하지만(boottrap=False 및 max_samples=1.0 설정) 기능을 샘플링하는 것(boottrap_features를 True로 설정 및/또는 max_features를 1.0보다 작은 값으로 설정)을 Random Subspaces 방법이라고 한다. 샘플링 기능을 사용하면 더 많은 예측 변수가 다양성을 얻을 수 있으며 더 낮은 분산을 위해 약간 더 많은 편향을 교환할 수 있다.
Random Forests
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators = 500, max_leaf_nodes = 16, n_jobs = -1)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)랜덤 포레스트(Random Forests)는 일반적으로 훈련 세트의 크기로 max_samples를 설정하여 배깅 방법(또는 때로는 패스팅)을 통해 훈련된 의사 결정 트리의 앙상블이다. 결정 트리를 구축하고 BaggingClassifier에 전달하는 대신보다 편리하고 의사 결정 트리에 최적화된 RandomForestClassifier 클래스를 사용할 수 있다. 윗 코드는 모든 가능한 CPU 코어를 사용하여 500개의 트리(각각의 최대 노드 수가 16으로 제한된)를 가진 랜덤 포레스트 분류기를 훈련시켰다. 랜덤 포레스트 알고리즘은 노드를 분할할 때 최상의 기능을 찾는 대신 기능의 무작위 하위 집합 중에서 최상의 기능을 찾는 추가적인 무작위성을 도입하였다. 이 알고리즘은 더 높은 편향을 낮은 분산으로 교환하며 일반적으로 전반적으로 더 나은 모델을 생성한다.
Feature Importance
랜덤 포레스트의 또 다른 훌륭한 특징은 각 특성의 상대적 중요성을 측정하기 쉽다. Scikit-Learn은 해당 기능을 사용하는 트리 노드가 평균적으로 불순도를 얼마나 줄이는지를 측정하여 기능의 중요성을 측정한다. 더 정확히는 각 노드의 가중치가 해당 노드와 관련된 훈련 샘플의 수와 동일하도록 가중 평균을 계산한다.
from sklearn.datasets import load_iris
iris = load_iris()
rnd_clf = RandomForestClassifier(n_estimators = 500, n_jobs = -1)
rnd_clf.fit(iris["data"], iris["target"])
for name, score in zip(iris["feature_names"], rnd_clf.feature_importances_):
print(name, score)
# sepal length (cm) 0.11249225099
# sepal width (cm) 0.0231192882825
# petal length (cm) 0.441030464364
# petal width (cm) 0.423357996355
Scikit-Learn은 훈련 후 각 기능에 대해이 점수를 자동으로 계산하고 결과를 모든 중요도의 합이 1이 되도록 조정한다. feature_importances_ 변수를 사용하여 결과에 액세스 할 수 있다. 아이리스 데이터 세트의 경우 가장 중요한 기능은 꽃잎 길이(44%)와 너비(42%)이다. 마찬가지로 MNIST 데이터 세트에서 랜덤 포레스트 분류기를 훈련하고 각 픽셀의 중요도를 플롯 하면 다음과 같은 이미지를 얻을 수 있다.
Boosting
부스팅(Boosting, 원래 hypothesis boosting이라고 함)은 여러 약한 학습기를 하나의 강력한 학습기로 결합할 수 있는 모든 앙상블 방법을 의미한다. 대부분의 부스팅 방법의 일반적인 아이디어는 예측기를 순차적으로 훈련하여 각 예측기를 이전 예측기를 수정하려고 시도하는 것이다. 사용할 수 있는 부스팅 방법은 많지만 가장 널리 사용되는 방법은 AdaBoost(Adaptive Boosting의 약자)와 Gradient Boosting이 있다.
AdaBoost
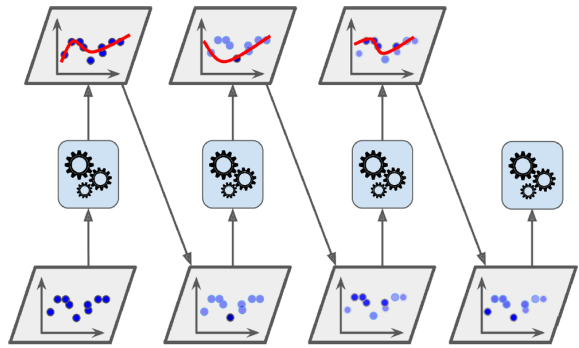
AdaBoost는 새로운 예측기가 이전 예측기의 오류를 보정하기 위해 이전 예측기가 학습하지 못한 학습 샘플에 더 많은 관심을 기울이는 방법 중 하나이다. 이로 인해 새로운 예측기는 점점 더 어려운 경우에 초점을 맞추게 된다. AdaBoost 분류기를 훈련시킬 때 알고리즘은 먼저 기본 분류기(예: 결정 트리)를 훈련하고 이를 사용하여 훈련 세트에 대한 예측을 수행한다. 알고리즘은 그런 다음 잘못 분류된 훈련 샘플의 상대적 가중치를 늘린다. 그런 다음 업데이트된 가중치를 사용하여 두 번째 분류기를 훈련하고 다시 훈련 세트에 대한 예측을 수행하고 샘플 가중치를 업데이트하고 이와 같은 과정을 반복한다.
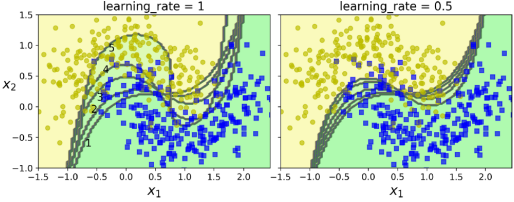
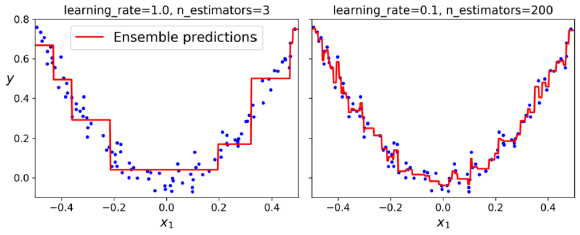
위 그림에서는 다섯 개의 연속적인 예측기의 결정 경계를 보여주며(이 경우 각 예측기는 RBF 커널을 사용한 과적합이 많이 제어된 SVM 분류기이다.), 오른쪽 그림은 학습 속도가 절반으로 감소된 경우를 나타낸다.(즉, 각 반복에서 오분류된 샘플 가중치가 절반만큼 증가된다.) 이러한 순차 학습 기술은 Gradient Descent와 몇 가지 유사점이 있다. 하지만 단일 예측기의 매개변수를 조정하여 비용 함수를 최소화하는 대신, AdaBoost는 점진적으로 앙상블에 예측기를 추가하여 전체적으로 더 나은 모델을 만든다.
모든 예측기가 훈련된 후 앙상블은 bagging 또는 pasting과 매우 유사하게 예측을 수행한다. 다만, 예측기는 가중치가 다르며 가중 훈련 세트 전체에서의 전반적인 정확도에 따라 가중치가 부여된다. 이러한 순차 학습 기술의 중요한 단점은 각 예측기가 이전 예측기의 훈련 및 평가가 완료된 후에만 훈련될 수 있으므로 병렬화(또는 부분적으로만 가능)할 수 없다는 것이다. 결과적으로 bagging이나 pasting만큼 잘 확장되지 않는다.
AdaBoost Algorithm

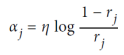
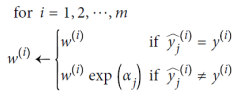
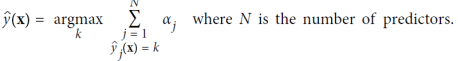
우선 각 인스턴스 가중치 𝑤^𝑖는 초기에 1/𝑚으로 설정된다. 첫 번째 예측기가 훈련되고, 가중 오류율 𝑟1이 다음과 같이 훈련 세트에서 계산된다. 그런 다음 예측기의 가중치 𝛼𝑗은 식 Predictore weight을 사용하여 계산된다. 여기서 𝜂은 학습률 하이퍼파라미터로 설정된다(기본값은 1). 예측기가 정확할수록 가중치가 높아진다. 만약 무작위로 추측한다면 가중치는 거의 0에 가까울 것이다. 그러나 그것이 종종 잘못된 경우(즉, 무작위 추측보다 정확도가 낮은 경우) 가중치는 음수가 된다. 그런 다음, AdaBoost 알고리즘은 식 Weight update rule을 사용하여 인스턴스 가중치를 업데이트한다. 이로 인해 잘못 분류된 인스턴스의 가중치가 증가한다. 그런 다음 모든 인스턴스 가중치가 정규화된다. 마지막으로, 업데이트된 가중치를 사용하여 새로운 예측기가 훈련되고, 전체 프로세스가 반복된다(새로운 예측기의 가중치가 계산되고, 인스턴스 가중치가 업데이트되고, 다른 예측기가 훈련되고, 이와 같은 과정을 반복). 원하는 수의 예측기에 도달하거나 완벽한 예측기가 발견되면 알고리즘이 중지된다. 예측을 수행하기 위해 AdaBoost는 간단히 모든 예측기의 예측을 계산하고, 예측기 가중치 𝛼𝑗를 사용하여 가중치를 부여한다. 예측된 클래스는 가중 투표의 과반수를 받는 클래스이다.
SAMME
Scikit-Learn은 SAMME(Multiclass Exponential loss function을 사용하는 Stagewise Additive Modeling)라는 AdaBoost의 다중 클래스 버전을 사용한다. 클래스가 두 개만 있는 경우 SAMME는 AdaBoost와 동일하다.
Gradient Boosting

from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(max_depth = 2)
tree_reg1.fit(X, y)
y2 = y - tree_reg1.predict(X)
tree_reg2 = DecisionTreeRegressor(max_depth = 2)
tree_reg2.fit(X, y2)
y3 = y2 - tree_reg1.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth = 2)
tree_reg3.fit(X, y3)
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))Gradient Boosting은 AdaBoost와 마찬가지로 각 예측기를 순차적으로 앙상블에 추가하여 이전 예측기를 보정한다. 그러나 이 방법은 AdaBoost가 매 반복마다 인스턴스 가중치를 조정하는 대신 새로운 예측기를 이전 예측기의 에러를 학습하려고 시도한다. 예를 들어, Gradient Tree Boosting 또는 Gradient Boosted Regression Trees (GBRT)를 사용하여 간단한 회귀를 설명한 위 코드를 보자. 먼저, 훈련 세트에 DecisionTreeRegressor를 적합시키고, 다음으로 첫 번째 예측기가 만든 잔차 오류로 두 번째 DecisionTreeRegressor를 훈련시킨다. 그런 다음 두 번째 예측기가 만든 잔차 오류로 세 번째 회귀 예측기를 훈련시킨다. 이제 세 개의 트리가 있는 앙상블이 있다. 간단한 방법으로 GBRT 앙상블을 훈련하는 방법은 Scikit-Learn의 GradientBoostingRegressor 클래스를 사용하는 것이다.
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegresor(max_depth = 2, n_estimator = 3, learning_rate = 1.0)
gbrt.fit(X, y)learning_rate 하이퍼파라미터는 각 트리의 기여를 조정한다. 0.1과 같은 낮은 값으로 설정하면 훈련 세트를 적합시키기 위해 더 많은 트리가 필요하지만 예측은 일반적으로 더 잘 일반화된다. 이것은 축소(shrinkage)라는 정규화 기술이다. 최적의 트리 수를 찾으려면 조기 중지를 사용할 수 있다.

import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
X_train, X_val, y_train, y_val = train_test_split(X, y)
gbrt = GradientBoostingRegressor(max_depth = 2, n_estimators = 120)
gbrt.fit(X_train, y_train)
errors = [mean_squared_error(y_val, y_pred)
for y_pred in gbrt.staged_predict(X_val)]
bst_n_estimators = np.argmin(errors) + 1
gbrt_best = GradientBoostingRegressor(max_depth = 2, n_estimators = bst_n_estimators)
gbrt_best.fit(X_train, y_train)이 코드는 120개의 트리로 GBRT 앙상블을 훈련시키고, 훈련의 각 단계에서 유효성 검사 오류를 측정하여 최적의 트리 수를 찾은 후, 최적의 트리 수를 사용하여 다른 GBRT 앙상블을 훈련시킨다. 또한, 최적의 트리 수를 찾기 위해 먼저 많은 수의 트리를 훈련한 다음 최적의 수를 찾는 대신 조기 중지를 실제로 중지하여 조기 중지를 구현할 수도 있다. warm_start = True로 설정하여 Scikit-Learn이 fit() 메서드를 호출할 때 기존 트리를 유지하도록 하여 증분 훈련을 허용한다. 이 코드는 연속 다섯 번의 반복동안 유효성 검사 오류가 향상되지 않으면 훈련을 중지한다. Stochastic Gradient Boosting은 GradientBoostingRegressor 클래스가 subsample 하이퍼파라미터도 지원한다. 이는 각 트리를 훈련할 때 사용할 훈련 인스턴스의 분수를 지정한다. subsample=0.25라면 각 트리는 무작위로 선택된 훈련 인스턴스의 25%에서 훈련된다. 이 기술은 더 높은 편향을 낮은 분산으로 교환한다. 또한 훈련 속도를 상당히 빠르다.
Stacking
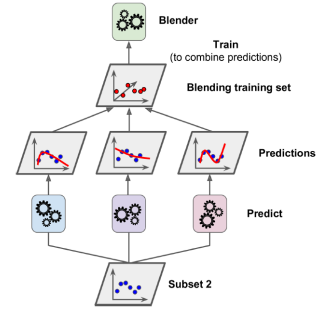
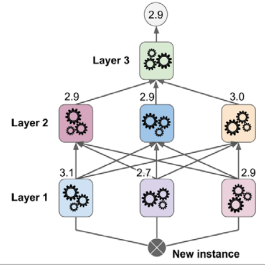
스태킹(Stacking, stacked generalization)은 간단한 아이디어에 기반한 기법으로, 앙상블의 모든 예측기의 예측을 결합하기 위해 단순한 함수(예: hard voting)를 사용하는 대신 이 결합을 수행할 모델을 훈련하는 것이다. 스태킹은 회귀 작업에서도 사용된다. 여기서 위 세 개의 예측기 각각이 다른 값을(3.1, 2.7, 2.9) 예측하고, 마지막 예측기(블렌더(blender) 또는 메타 학습기(meta learner)라고 함)는 이러한 예측을 입력값으로 사용하여 예측(3.0)을 수행한다. 블렌더를 훈련시키기 위해 일반적인 접근 방법은 홀드아웃 세트(hold-out set)를 사용하는 것이다. 먼저, 훈련 세트를 두 개의 하위 세트로 나눈다. 첫 번째 하위 세트는 첫 번째 층의 예측기를 훈련하는 데 사용된다. 그다음, 첫 번째 층의 예측기는 두 번째(홀드아웃) 세트에 대한 예측을 수행한다. 이렇게 하면 예측이 "깨끗"하게 유지되므로, 예측기는 훈련 중 이러한 인스턴스를 본 적이 없다. 이 예측 값을 입력 특성으로 사용하여(이를 통해 이 새로운 훈련 세트는 3차원이 된다) 대상 값을 유지한 채 새로운 훈련 세트를 만들고, 블렌더는 이 새로운 훈련 세트에서 훈련되어 첫 번째 층의 예측을 기반으로 대상 값을 예측하도록 학습한다. 사실 이 방법으로 여러 가지 다른 블렌더를 훈련하는 것도 가능하다.(예: 선형 회귀를 사용하는 하나, 랜덤 포레스트 회귀를 사용하는 다른 하나) 이를 통해 블렌더의 전체 층을 얻을 수 있다. 핵심은 훈련 세트를 세 개의 하위 세트로 나누는 것이다. 첫 번째 하위 세트는 첫 번째 층을 훈련하는 데 사용되며, 두 번째 하위 세트는 첫 번째 층의 예측기의 예측을 사용하여 두 번째 층을 훈련하는 데 사용되며, 세 번째 하위 세트는 두 번째 층의 예측기의 예측을 사용하여 세 번째 층을 훈련하는 데 사용된다. 이렇게 하면 각 층을 순차적으로 거치면서 새 인스턴스에 대한 예측을 생성할 수 있다.
'컴퓨터공학 > AI' 카테고리의 다른 글
| 기계 학습 9. Unsupervised Learning Techniques (1) | 2023.11.17 |
|---|---|
| 기계 학습 8. 차원 축소(Dimensionality Reduction) (0) | 2023.10.28 |
| 기계 학습 6. 의사 결정 트리(Decision Trees) (1) | 2023.10.19 |
| 기계 학습 5. Support Vector Machine(SVM) (1) | 2023.10.19 |
| 기계 학습 4. 회귀(Regression) 분석 (1) | 2023.10.19 |




댓글