서론
Markov Decision Process(MDP)는 강화학습에서 문제 정의할 때 많이 사용되는 기법이다. Dynamic Programming는 MDP에서 정의한 수식들을 풀어내기 위한 방법을 말한다.
The Markov chain
Markov property & Markov chain
Markov Decision Process(MDP)에 대해 알기 전에 Markov property와 Markov chain에 대해 알아야 한다. Markov property란 미래는 과거가 아닌 현재에만 의존하는 조건이다. Markov chain은 다음 상태를 예측하기 위해 이전 상태가 아닌 현재 상태에만 의존하는 확률 모델로 미래는 과거로부터 조건부 독립임을 말하는 모델들을 말한다. 이때, Markov chain은 Markov property을 엄격히 따른다.
대표적인 예시로 날씨 예측이 있다. 오늘의 날씨가 습하다면 곧 비가 온다는 근거가 되지만, 과거에 날씨가 흐렸다는 것은 미래 비가 올 가능성에 대한 근거가 되지 못한다. 즉, 오로지 현재 상태만을 가지고 다음에 올 상황을 예측하는 것을 Markov chain이라 한다.
Transition & Transition probability
MDP의 이해를 돕기 위해 Transition과 Transition probability 용어에 대해 간략히 설명하자면, Transition은 한 상태에서 다른 상태로 이동하는 것을 의미한다. Transition probability은 한 상태에서 다른 상태로 이동할 경우의 확률을 말한다.
Transition probabilities을 테이블 형태로 정리할 수 있으며 이를 Markov table이라고 하며 Transition probability이 있는 상태 다이어그램(state diagram) 형태의 마르코프 체인(Markov chain)으로도 표현이 가능하다.


The Markov Decision Process
Markov Decision Process(MDP)는 Markov chain의 확장으로 의사 결정 상황을 모델링하기 위한 수학적 프레임워크를 제공한다. MDP는 거의 모든 강화 학습 문제를 모델링할 수 있다.
MDP의 다섯 가지 중요 요소
- States(S, 상태): 에이전트(agent)가 실제로 있을 수 있는 상태의 집합
- Actions(A, 행동): 한 상태에서 다른 상태로 이동하기 위해 에이전트(agent)가 수행할 수 있는 행동의 집합
- Transition probability(전환 확률): 어떤 동작을 수행하여한 상태에서 다른 상태로 이동할 확률

- Reward probability(보상 확률): 에이전트가 어떤 행동을 수행하여 한 상태에서 다른 상태로 이동하여 얻을 수 있는 보상의 확률

- Discount factor(𝛾): 현재 및 미래 보상의 중요성을 제어하는 보정값
Rewards and Returns
에이전트는 즉각적인 보상 대신 환경으로부터 받는 보상의 총량(누적 보상, cumulative rewards)을 최대화하려고 한다.


에이전트가 환경으로부터 받는 보상의 총량을 반환(returns, 𝑅𝑡)라고 한다. 𝑟𝑡+1은 한 상태에서 다른 상태로 이동하기 위해 𝑎𝑡 작업을 수행하는 동안 시간 단계 𝑡에서 에이전트가 받는 보상이다.
Episodic and Continuous Tasks
Episodic task는 종료 상태(종료)가 있는 작업을 의미한다. RL에서 에피소드는 초기 상태에서 최종 상태까지 agent-environment 상호 작용으로 간주된다. 예로 자동차 경주 게임에서 "게임을 시작(초기 상태)하고 게임이 끝날 때까지 플레이(최종 상태)"까지를 에피소드라고 한다. 게임이 끝나면 게임을 다시 시작하여 다음 에피소드를 시작하며 이전 게임에서 있었던 위치와 관계없이 초기 상태에서 시작한다. 따라서 각 에피소드는 서로 독립적입니다.
Continuous task는 종료 상태가 없는 연속적인 작업을 의미한다. 예를 들어, 개인 보조 로봇에는 최종 상태가 없다.
Discount Factor
에이전트의 목표는 Return(Rt)을 극대화하는 것이다. Episodic task의 경우 Rturn을 다음과 같이 정의할 수 있다.

여기서 𝑇는 에피소드의 마지막 상태이다. 하지만 Continuous task의 경우 최종 상태가 없으므로 반환을 다음과 같이 정의하면 합계는 무한대가 된다.

그렇다면 절대 멈추지 않는다면 어떻게 수익을 극대화할 수 있을까요? 이를 해결하기 위해 Discount Factor(𝛾)라는 개념을 도입이 되었다. Episodic task과 Continuous task에 대한 통합 개념에서 다음과 같이 Discount Factor(𝛾)로 Return(Rt)을 정의할 수 있다.

Discount Factor(𝛾)는 미래 보상과 즉각적인 보상에 얼마나 많은 중요성을 부여할지 결정한다. 𝛾계수의 값은 [0, 1] 범위에 있다.(1보다 클 경우 현재보다 미래가 중요하다는 의미가 되므로 Markov chain이 아니게 된다.) 𝛾 = 0이면 즉각적인 보상(현재)이 더 중요하며 𝛾 = 1이면 향후 보상이 더 중요함을 의미한다. 𝛾은 하이퍼파라미터(사용자가 직접 세팅하는 값)이며 일반적으로 0.2에서 0.8 사이 값을 넣는다.
Policy Function (𝝅)
Policy Function(정책)은 각 상태에서 수행할 행동을 의미한다.(States에서 행동으로 매핑) 우리는 궁극적으로 각 상태에서 수행할 올바른 행동을 지정하는 최적의 정책을 찾아야 한다.

Value Function (State Value Function)
Value Function은 에이전트가 정책으로 특정 상태에 있는 것이 얼마나 좋은지 지정한다. 다음과 같이 가치 함수를 정의할 수 있다.(time step 𝑡에서 정책𝜋에 따라 상태𝑠에서 시작하는 예상(𝔼)을 반환(𝑅𝑡))

State Value Function(상태 가치 함수)는 정책에 따라 다르며 우리가 선택한 정책에 따라 달라진다.
다음은 테이블에서 가치 함수를 나타낸다.
| State | Value |
| State1 | 0.3 |
| State2 | 0.7 |
이렇게 나타낼 수 있기에 가치함수 기반 RL을 테이블 솔루션 방법이라고 부르는 이유이다. 두 개의 States가 있고 이 두 States가 모두 정책 𝜋을 따른다고 가정해 보자. 이 두 States의 Value을 기반으로 에이전트가 정책에 따라 해당 상태에 있는 것이 얼마나 좋은지 알 수 있다. 앞의 표를 기준으로 State 2에 있는 것이 값이 높기 때문에 좋다는 것을 알 수 있다.
State-Action Value Function (Q function, Q(s,a))
에이전트가 정책𝜋이 있는 상태에서 특정 작업을 수행하는 것이 얼마나 좋은지 지정한다. Q 함수(Q function)는 정책을 따르는 상태 𝑠에서 행동 𝑎을 취하는 가치를 나타낸다.

가치 함수와 Q 함수의 차이점은 가치 함수는 State에 대한 기대값을, Q 함수는 어느 State에서 Action의 기대값을 나타낸다. 상태 값 함수와 마찬가지로 Q 함수는 표(Q 테이블)에서 볼 수 있다. 두 가지 상태와 두 가지 동작이 있다고 가정해 보자. Q 테이블은 다음과 같다.
| State | Action | Value |
| State1 | Action1 | 0.2 |
| State1 | Action2 | 0.1 |
| State2 | Action1 | 0.25 |
| State2 | Action2 | 0.45 |
Q 테이블은 가능한 모든 상태 조치 쌍의 값을 보여준다. 이 표를 보면 State1에서 Action1을 수행하고 State2에서 Action2를 수행하는 것이 가치가 높기 때문에 더 나은 옵션이라는 결론에 도달할 수 있다.
Recursive Relationships in Value Function
강화 학습 전반에 걸쳐 사용되는 가치 함수의 기본 속성은 다음과 같은 재귀 관계를 만족한다는 것이다.

Bellman Equation and Optimality
미국 수학자 Richard Bellman의 이름을 딴 Bellman 방정식은 MDP를 푸는 데 도움이 된다. MDP를 해결한다는 것은 실제로 최적의 정책(optimal policy)과 가치 함수(optimal value function)를 찾는 것을 의미한다. 서로 다른 정책에 따라 다양한 가치 함수가 있을 수 있다. 다양한 가치 함수 중에서 최적 가치 함수𝑉(𝑠)는 다음과 같이 다른 모든 가치 함수와 비교하여 최댓값을 산출하는 함수로 구할 수 있다.

유사하게, 최적 정책은 최적의 가치 함수를 초래하는 정책이다. 최적가치함수𝑉(𝑠)는 다른 모든 가치함수(maximum return)에 비해 높은 값을 가지므로 Q함수의 최댓값이 된다. 따라서 최적 가치 함수는 다음과 같이 Q 함수의 최댓값을 취함으로써 쉽게 계산할 수 있다.
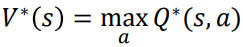
Bellman 방정식의 value function은 아래와 같다.

cont'
아래 그림은 상태(State)의 가치와 후속 상태의 가치 사이의 관계를 표현한 것이다. 각각의 흰 원은 상태를 나타내고 각각의 어두운 원은 상태-행동(State-Action) 쌍을 의미한다. 맨 위에 있는 루트 노드인 상태 𝑠에서 시작하여 에이전트는 정책 𝜋에 따라 일련의 작업(다이어그램에 3개가 표시됨) 중 하나를 수행할 수 있다. 이들 각각에서 환경은 확률 𝑝에 의해 주어진 반응에 따라 보상 𝑟과 함께 여러 다음 상태 중 하나인 𝑠′(그림에 두 개가 표시됨)로 응답할 수 있다. Bellman 방정식은 모든 가능성에 대해 평균을 내며 각 가능성에 대해 발생 확률에 따라 가중치를 부여한다. 시작 상태의 값은 예상되는 다음 상태의 (discounted) 값과 그 과정에서 예상되는 보상을 더한 값과 같아야 한다.
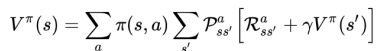

Q function에 대한 Bellman 방정식

Bellman 최적 방정식

Dynamic Programming
일반적인 동적 프로그래밍(Dynamic Programing, DP)은 복잡한 문제를 간단한 여러 개의 문제로 나누어 푸는 방식을 말한다. 이것은 부분 문제 반복과 최적 부분 구조를 가지고 있는 알고리즘을 일반적인 방법에 비해 더욱 적은 시간 내에 풀 때 사용한다.
DP에서는 복잡한 문제를 한 번에 하나씩 해결하는 대신 문제를 간단한 하위 문제로 나눈 다음 각 하위 문제에 대해 솔루션을 계산하고 저장한다. 동일한 하위 문제가 발생하면 다시 계산하지 않고 대신 이미 계산된 솔루션을 사용한다. 예를 들어, MDP에서는 일반적으로 유한한 환경이라 가정한다. 이 말은 즉, state, action, reward set, 𝑆, 𝐴, 보상확률이 유한하다면 그 dynamics는 transition 확률에 의해 주어진다는 것을 의미한다. 이러한 알고리즘을 가지고 Bellman 최적 방정식을 풀면 최적의 정책을 찾거나 Bellman 최적 방정식을 풀 때 사용한다.
Bellman을 푸는 대표적인 알고리즘으로 value iteration, policy iteration이 있다.
value iteration
value iteration은 처음 시작 시 랜덤 한 함수로 초기화한다. 당연히 랜덤 값 함수는 최적 값 함수가 아닐 수 있으므로 최적 값 함수를 찾을 때까지 반복적인 방식으로 새롭게 개선된 값 함수를 찾는 알고리즘이다. 이를 통해 최적의 가치 함수를 찾으면 최적의 정책을 쉽게 도출할 수 있다.
step
1. 먼저 랜덤 값 함수, 즉 각 상태에 대한 랜덤 값을 초기화한다.
2. 그런 다음 Q(s, a)의 모든 상태 동작 쌍에 대해 Q 함수를 계산한다.
3. 그런 다음 Q(s, a)의 최댓값으로 가치 함수를 업데이트한다.
4. 가치 함수의 변화가 매우 적을 때까지 이 단계를 반복한다.

policy iteration
policy iteration은 무작위 정책으로 시작한 다음 해당 정책의 가치 함수를 찾는다. 가치 함수가 최적이 아니면 새로운 개선된 정책을 찾도록 최적의 정책을 찾을 때까지 이 과정을 반복하는 알고리즘이다. 정책 반복할 때 정책 평가와 정책 개선이라는 두 단계를 거친다. 정책 평가(Policy evaluation)는 무작위로 추정한 정책의 가치함수 평가하는 단계와 정책개선(Policy improvement)은 가치함수를 평가하여 최적이 아닌 경우 새로운 개선정책을 찾는 단계이다.
step
1. 먼저 랜덤 정책을 초기화한다.
2. 그런 다음 해당 무작위 정책에 대한 가치 함수를 찾고 최적인지 확인하기 위해 평가한다. 이를 정책 평가라고 한다.
3. 최적이 아닌 경우 정책 개선이라는 새로운 개선 정책을 찾는다.
4. 최적의 정책을 찾을 때까지 이 단계를 반복한다.

Frozen Lake Problem
Frozen Lake Problem은 MDP를 DP로 푸는 대표적인 예시이다.
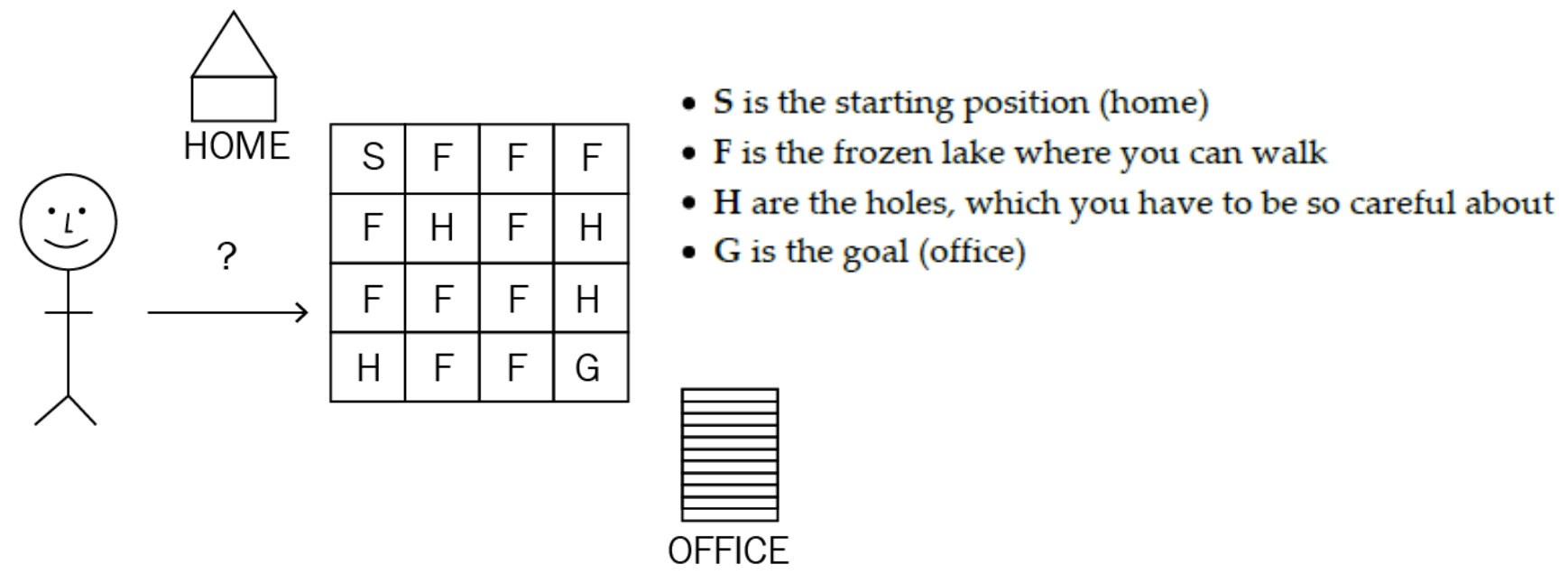
Frozen Lake Problem의 환경은 집에서 사무실까지 이어지는 얼어붙은 호수가 있고 사무실에 가려면 얼어붙은 호수 위를 걸어야 한다. 하지만 얼어붙은 호수에는 구멍이 있으므로 구멍에 갇히지 않도록 얼어붙은 호수 위를 걷는 동안 조심해야 한다.
S는 집이자 시작 위치, F는 걸을 수 있는 얼은 호수 위, H는 조심해야 할 구멍, G은 목표이자 사무실이다.
- 이 환경에서의 에이전트의 목표는 H에 갇히지 않고 S에서 G로 가는 최적의 경로를 찾는 것이다.
- 에이전트가 얼어붙은 호수 위를 올바르게 걸으면 보상으로 +1점을 주고 구멍에 빠지면 0점을 주어 에이전트가 올바른 행동을 결정할 수 있도록 한다.
- 에이전트는 이제 최적의 정책을 찾으려고 노력할 것이다.
- 최적의 정책은 에이전트의 보상을 최대화하는 올바른 경로를 취하는 것을 의미한다.
- 에이전트가 보상을 최대화하는 경우 분명히 에이전트는 구멍을 건너뛰고 목적지에 도달하는 방법을 배우고 있는 것이다.
문제를 MDP로 모델링할 수 있다.
- States(상태): 상태 집합입니다. 여기에는 16개의 상태(그리드의 각 작은 사각형 상자)가 있다.
- Actions(액션): 가능한 모든 액션 세트(왼쪽, 오른쪽, 위, 아래; 에이전트가 얼어붙은 호수 환경에서 취할 수 있는 네 가지 가능한 액션).
- Transition probabilities(전이 확률): 행동을 수행함으로써 한 상태에서 다른 상태로 이동할 확률 a.
- Rewards probabilities(보상 확률): 행동 a를 수행하여한 상태에서 다른 상태로 이동하는 동안 보상을 받을 확률
이제 Bellman Optimality 방정식을 사용하여 가치 함수와 Q 함수를 나타낸다. 이 방정식을 풀면 최적의 정책을 찾을 수 있다. 여기서 방정식을 푸는 것은 최적의 가치함수를 찾는 것을 의미하며 정책은 최대수익률을 가져온다.
Bellman 최적 방정식을 풀기 위해 동적 프로그래밍을 사용할 것이다. DP를 적용하기 위해서는 기본적으로 모델 환경의 전환 확률과 보상 확률을 미리 알고 있어야 한다.
Solving a Bellman equation using dynamic programming (Value Iteration)
import gym
import numpy as np
from IPython import display
import matplotlib.pyplot as plt
import time
%matplotlib inline
#환경 세팅
env = gym.make("FrozenLake-v0")
env = env.unwrapped
env.render()
#value iteration알고리즘
def value_iteration(env, gamma=1.0):
#값 테이블을 0으로 초기화
value_table = np.zeros(env.observation_space.n)
#ithreshold값 설정
no_of_iterations = 10000
threshold = 1e-20
#Q(s, a) = Transition probability * (Reward probability + gamma * value_of_next_state)
for i in range(no_of_iterations):
#각 반복에서 값 테이블을 updated_value_table에 복사
updated_value_table = np.copy(value_table)
#이제 상태의 각 작업에 대한 각 계산 Q 값 및 최대 Q 값으로 상태 값 업데이트
for state in range(env.observation_space.n):
#현재 상태에 대한 Q value, Q_value = [Q(s, a1), Q(s, a2), Q(s, a3), Q(s, a4)]
Q_value = []
for action in range(env.action_space.n):
#Q value에 대한 각각의 action, next_states_rewards = [rewards(s, a1, s2), rewards(s, a1, s3)...]
next_states_rewards = []
for next_sr in env.P[state][action]:
trans_prob, next_state, reward_prob,_ = next_sr
next_states_rewards.append((trans_prob * (reward_prob + gamma * updated_value_table[next_state])))
Q_value.append(np.sum(next_states_rewards))
value_table[state] = max(Q_value)
#수렴에 도달했는지, 즉 값 테이블과 업데이트 값 테이블의 차이가 매우 작은지 여부를 확인한다.
#하지만 os가 매우 작은지 어떻게 알 수 있을까? 임계값을 설정한 다음 차이가 임계값보다 작은지 확인하고
#작으면 루프를 끊고 가치 함수를 최적의 가치 함수로 반환한다.
if(np.sum(np.fabs(updated_value_table - value_table)) <= threshold):
print("Value-iteration converged at iteration# %d." %(i+1))
break
return value_table
#최적의 정책 찾는 함수
def extract_policy(value_table, gamma = 1.0):
#정책을 0으로 초기화
policy = np.zeros(env.observation_space.n, np.int32)
for state in range(env.observation_space.n):
#상태에 대한 Q 테이블 초기화
Q_table = np.zeros(env.action_space.n)
#상태의 모든 작업에 대한 Q value 계산
for action in range(env.action_space.n):
for next_sr in env.P[state][action]:
trans_prob, next_state, reward_prob, _ = next_sr
Q_table[action] += (trans_prob * (reward_prob + gamma * value_table[next_state]))
#Q value이 최대인 행동을 상태의 최적 행동으로 선택
policy[state] = np.argmax(Q_table)
return policy
#에피소드 플레이 보여주는 함수
def play(env, optimal_policy, max_step = 1000):
state = 0
for i in range(max_step):
env.render()
time.sleep(1)
display.clear_output(wait=True)
display.display(plt.gcf())
state,_,done,_ = env.step(optimal_policy[state])
if done:
env.render()
break
#정의한 함수들 실행
optimal_value_function = value_iteration(env=env, gamma=1.0)
optimal_policy = extract_policy(optimal_value_function, gamma=1.0)
print(optimal_policy)
#정의한 함수들을 토대로 실행
play(env, optimal_policy)Solving a Bellman equation using dynamic programming (Policy Iteration)
import gym
import numpy as np
from IPython import display
import matplotlib.pyplot as plt
import time
%matplotlib inline
#환경 세팅
env = gym.make("FrozenLake-v0")
env = env.unwrapped
env.render()
#policy iteration알고리즘
def compute_value_function(policy, gamma=1.0):
#값 테이블을 0으로 초기화
value_table = np.zeros(env.nS)
#threshold 설정
threshold = 1e-10
while True:
#값 테이블을 updated_value_table에 복사
updated_value_table = np.copy(value_table)
#환경의 각 상태에 대해 정책에 따라 작업을 선택하고 값 테이블을 계산
for state in range(env.nS):
action = policy[state]
#선택한 작업으로 값 테이블 작성
value_table[state] = sum([trans_prob * (reward_prob + gamma * updated_value_table[next_state]) for trans_prob, next_state, reward_prob, _ in env.P[state][action]])
if(np.sum((np.fabs(updated_value_table - value_table))) <= threshold):
break
return value_table
#최적의 정책 찾는 함수
def extract_policy(value_table, gamma = 1.0):
#정책을 0으로 초기화
policy = np.zeros(env.observation_space.n, np.int32)
for state in range(env.observation_space.n):
#상태에 대한 Q 테이블 초기화
Q_table = np.zeros(env.action_space.n)
#상태의 모든 작업에 대한 Q 값 계산
for action in range(env.action_space.n):
for next_sr in env.P[state][action]:
trans_prob, next_state, reward_prob, _ = next_sr
Q_table[action] += (trans_prob * (reward_prob + gamma * value_table[next_state]))
#Q값이 최대인 행동을 상태의 최적 행동으로 선택
policy[state] = np.argmax(Q_table)
return policy
#에피소드 플레이 보여주는 함수
def play(env, optimal_policy, max_step = 1000):
state = 0
for i in range(max_step):
env.render()
time.sleep(1)
display.clear_output(wait=True)
display.display(plt.gcf())
state,_,done,_ = env.step(optimal_policy[state])
if done:
env.render()
break
#정의한 함수들 실행
optimal_policy = policy_iteration(env)
print(optimal_policy)
#정의한 함수들을 토대로 실행
play(env, optimal_policy)주섬주섬
중간중간의 공식들은 확률과 통계와 랜던변수 관련한 사전 지식이 있어야 이해할 수 있다.
최적의 Discount Factor을 찾는 공식은 없으며 해당 상황에 맞게 향후 보상이 중요하면 1에 가깝게 즉각적인 보상이 중요하면 0에 가깝게 우리가 예상하고 찾아 세팅해야 한다.
위에 적은 DP코드들은 reward를 최댓값을 찾는 것이지 최소로 목표로 도착하는 코드가 아니므로 사무실에 도착하는 데 오래 거릴 것이다.
참고
GitHub - openai/gym: A toolkit for developing and comparing reinforcement learning algorithms.
A toolkit for developing and comparing reinforcement learning algorithms. - GitHub - openai/gym: A toolkit for developing and comparing reinforcement learning algorithms.
github.com
'컴퓨터공학 > AI' 카테고리의 다른 글
| 강화 학습 6.Deep Learning Fundamentals (0) | 2023.05.09 |
|---|---|
| 강화 학습 5.Multi-Armed Bandit (MAB)Problem (0) | 2023.04.25 |
| 강화 학습 4.Temporal Difference(TD) Learning (0) | 2023.04.18 |
| 강화 학습 3.Monte Carlo(MC) Methods (0) | 2023.04.04 |
| 강화 학습 1.기본 개념 (0) | 2023.03.11 |




댓글