서론
이전 장에서 RL 및 여러 RL 알고리즘의 기본 개념과 RL 문제를 MDP(Markov Decision Process)로 모델링하는 방법에 대해 배웠다. MDP를 해결하는 데 사용되는 다양한 모델 기반(model-based) 및 모델 없는(model-free) 알고리즘도 보았다. 이제, RL의 고전적인 문제 중 하나인 MAB(Multi-Armed Bandit) 문제를 볼 것이다.
MDP는 일련의 상태(state)와 행동(action)의 시퀀스를 관찰하고, 각 시점에서의 보상(reward)을 최대화하기 위한 최적의 정책(policy)을 찾는 문제로 상태와 행동의 시퀀스를 고려하여 최적의 정책을 찾는 것이 목표이다. 반면, MAB 문제에서는 여러 개의 선택(arm) 중에서 최적의 선택을 찾는 것이 목표이다. MAB 문제에서는 각 선택마다 불확실한 보상이 주어지며, 여러 번 시도하면서 보상 분포를 학습하여 최적의 선택을 찾는 것이 중요하다.
Multi-Armed Bandit (MAB) Problem
강화학습에서 Multi-Armed Bandit(MAB) 문제는 어떤 선택(arm)을 하여 보상을 최대화하는 것을 목표로 하는 문제이다. MAB문제는 이름처럼 실제로 슬롯머신으로, arm(lever)을 당기고 무작위로 생성된 확률 분포에 따라 지불금(reward)을 받는 카지노에서 플레이하는 도박 게임이다. 여기서 여러 개의 arm 중에서 가장 높은 보상을 주는 arm을 선택해야 한다. 각각의 arm은 불확실한 보상을 주기 때문에 보상을 최대화하는 전략을 찾기 위해서는 여러 번 시도하면서 보상 분포를 학습해야 한다. 하나의 슬롯머신을 one-armed bandit이라고 하고, 여러 대의 슬롯머신이 있는 경우 multi-armed bandits 혹은 k-armed bandit이라고 한다.
각 슬롯머신이 자체 확률 분포에서 보상을 제공한다. 우리는 어떤 슬롯머신이 일련의 시간 동안 최대 누적 보상을 제공하는지 알아내는 것이 목표이다. 그래서 각 타임스텝 𝑡에서 에이전트는 행동 𝑎𝑡, 즉 슬롯머신에서 팔을 뽑아 리워드 𝑟𝑡를 받는데, 우리 에이전트의 목표는 누적 리워드를 최대화하는 것이다. arm의 𝑄(𝑎) 가치를 arm을 당겨 받는 평균 보상으로 정의한다. 따라서 최적의 arm은 최대 누적 보상을 사용하는 arm이다.

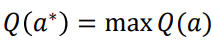
우리 에이전트의 목표는 최적의 arm을 찾고 후회(regret)를 최소화하는 것입니다. 후회는 k arm 중 어느 것이 최적인지 아는 비용으로 정의할 수 있다. 최고의 arm을 찾는 과정에서 모든 arm을 탐색하거나 아니면 이미 최대 누적 보상을 제공한 arm을 선택하는 탐색-착취(exploration-exploitation) 딜레마가 발생한다. 이 딜레마를 해결하는 방법은 아래와 같다.
- Epsilon-greedy policy
- Softmax exploration
- Upper confidence bound algorithm
- Thomson sampling technique

MDP와 다른 점
Multi-Armed Bandit Problem은 상태가 없고(Stateless), 각 arm에는 고정된 보상 분배가 있다. 이전에 어떤 arm을 당겼는지에 의존하지 않는다. 즉, 모든 환경은 독립적이다. MAB의 목표는 모든 arm의 보상 분포를 탐색한 다음 계속해서 최고의 것을 끌어내는 것이다.
Markov Decision Process은 상태가 있다. bandit problems를 모든 상태가 터미널(종료 상태)인 MDP로 볼 수 있다. 이 경우 모든 결정 시퀀스의 길이는 1이며 후속 풀은 서로 영향을 미치지 않는다.
Strategies
다음 예시를 실행하기 이전에 터미널에 아래와 같은 명령어를 입력하자. 다음 예시들을 모두 같은 환경에서 돌리면 같은 결과가 나와야 한다.
git clone https://github.com/JKCooper2/gym-bandits.git
cd gym-bandits
pip3 install –e .
pip3 install seaborn
Epsilon-greedy Policy
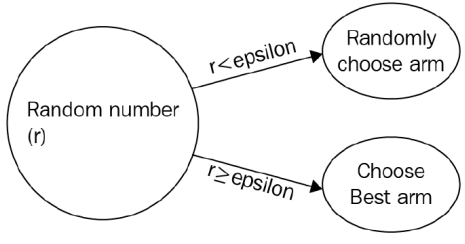
epsilon-greedy 정책에서 확률이 1-epsilon로는 최상의 arm을 선택하거나 확률 epsilon으로 무작위로 팔을 선택한다.
import gym_bandits
import gym
import numpy as np
import math
import random
env = gym.make("BanditTenArmedGaussian-v0")
env.action_space
#변수 초기화
#반복 수
num_rounds = 20000
#각 arm의 보상의 연속
count = np.zeros(10)
#각 arm의 보상 합계
sum_rewards = np.zeros(10)
#평균 보상인 Q value
Q = np.zeros(10)
#epsilon greedy policy
def epsilon_greedy(epsilon):
rand = np.random.random()
if rand < epsilon:
action = env.action_space.sample()
else:
action = np.argmax(Q)
return action
#슬롯 돌리기
for i in range(num_rounds):
#epsilon greedy을 사용하여 arm을 선택
arm = epsilon_greedy(0.5)
#보상 획득
observation, reward, done, info = env.step(arm)
#해당 arm의 수를 업데이트
count[arm] += 1
#arm에서 얻은 보상 합계
sum_rewards[arm]+=reward
#arm의 평균 보상인 Q value을 계산
Q[arm] = sum_rewards[arm]/count[arm]
print('The optimal arm is {}'.format(np.argmax(Q)))Softmax Exploration Algorithm
Boltzmann exploration이라고도 알려진 Softmax exploration은 최적의 적기(bandit)를 찾는 데 사용되는 또 다른 전략이다. epsilon-greedy 정책에서는 모든 non-best arm을 동등하게 고려하지만 Softmax 탐색에서는 볼츠만 분포의 확률을 기반으로 arm을 선택한다. 즉, 모든 arm의 평균 보상을 기준으로 줄을 세워 가장 높은 평균 보상을 주는 arm을 선택한다. arm을 선택할 확률은 다음과 같다.(𝜏: 탐색할 수 있는 임의의 arm 수를 지정하는 하이퍼파라미터 변수) 𝜏가 높으면 모든 arm이 동등하게 탐색되지만, 𝜏가 낮으면 보상이 높은 arm이 선택된다.
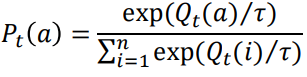
import gym_bandits
import gym
import numpy as np
import math
import random
env = gym.make("BanditTenArmedGaussian-v0")
env.action_space
#변수 초기화
#반복 수
num_rounds = 20000
#각 arm의 보상의 연속
count = np.zeros(10)
#각 arm의 보상 합계
sum_rewards = np.zeros(10)
#평균 보상인 Q value
Q = np.zeros(10)
#sofmax exploration
def softmax(tau):
total = sum([math.exp(val/tau) for val in Q])
probs = [math.exp(val/tau)/total for val in Q]
threshold = random.random()
cumulative_prob = 0.0
for i in range(len(probs)):
cumulative_prob += probs[i]
if(cumulative_prob > threshold):
return i
return np.argmax(probs)
for i in range(num_rounds):
#sofmax를 사용하여 arm 선택
arm = softmax(0.5)
#보상 획득
observation, reward, done, info = env.step(arm)
#해당 arm의 수를 업데이트
count[arm] += 1
#arm에서 얻은 보상 합계
sum_rewards[arm]+=reward
#arm의 평균 보상인 Q value을 계산
Q[arm] = sum_rewards[arm]/count[arm]
print('The optimal arm is {}'.format(np.argmax(Q)))The Upper Confidence Bound Algorithm
epsilon-greedy 및 softmax 탐색을 통해 확률이 있는 임의 작업을 탐색한다. 랜덤 액션은 다양한 arm을 탐색하는 데 유용하지만, 좋은 보상을 전혀 주지 않는 액션을 시도하게 만들 수도 있다. 또한 실제로는 좋지만 초기 라운드에서 보상이 좋지 않은 arm을 놓치고 싶지 않다. 그래서 Upper Confidence Bound(UCB)이라는 새로운 알고리즘을 사용한다. 불확실성에 직면한 낙관주의(optimism)라는 원칙에 기초한다. UCB 알고리즘은 신뢰 구간(confidence interval)을 기반으로 최상의 arm을 선택하는 데 도움이 된다.
예를 들어, 두 개의 arm이 있다고 하자. 이 두 arm을 당기고 Arm1이 우리에게 0.3 보상을 주고 Arm2가 우리에게 0.8 보상을 주는 것을 발견했다. 하지만 한 라운드의 arm을 당기는 것으로 Arm2가 우리에게 최고의 보상을 줄 것이라고 결론을 내리면 안 된다. arm을 여러 번 당기고 각 arm에서 얻은 보상의 평균값을 취하여 평균이 가장 높은 팔을 선택해야 한다. 하지만 각 arm에 대한 정확한 평균값을 어떻게 찾을 수 있을까? 여기에서 신뢰 구간이 등장한다. 신뢰 구간은 arm의 평균 보상 값 내의 구간을 지정한다. Arm1의 신뢰구간이 [0.2, 0.9]이면 Arm1의 평균값이 0.2: 신뢰 하한(lower confidence bound) / 0.9: 신뢰 상한 구간(upper confidence bound)에 있음을 의미한다. UCB는 UCB가 탐색한 높은 기계를 선택한다.
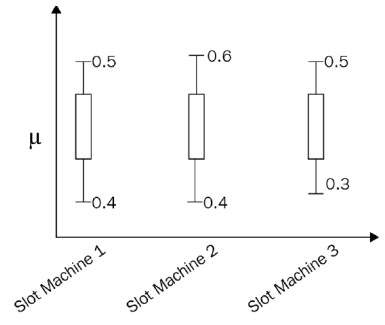
또 다른 예시로 3개의 슬롯머신이 있고 각각의 슬롯 머신을 10번 플레이했다고 가정해 보자. 이 3개의 슬롯 머신의 신뢰 구간은 다음 다이어그램에 표시된다. 슬롯 머신 3의 UCB가 높은 것을 볼 수 있다. 그러나 슬롯머신 3번이 10번 뽑는 것만으로 좋은 보상을 줄 것이라고 결론을 내려서는 안 된다.
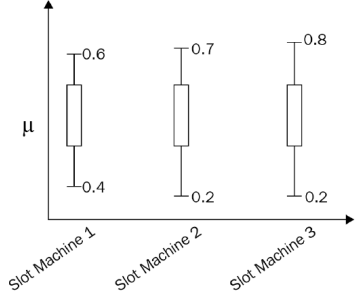
팔을 몇 번 더 당기면 신뢰 구간이 더 정확해진다. 따라서 시간이 지남에 따라 다음 다이어그램과 같이 신뢰 구간이 좁아지고 실제 값으로 축소된다.
UCB의 아이디어는 매우 간단하다. 평균 보상(착취)과 신뢰 상한의 합(탐색)이 높은 작업(arm)을 선택한다. arm을 당기고 보상을 받고, arm의 보상 및 신뢰 범위 업데이트한다. UCB는 다음과 같이 계산이 된다. 𝑁(𝑎)는 arm을 당긴 횟수이고 𝑡는 총 라운드 보상이다. 𝑎(arm)를 선택할 때마다 불확실성이 줄어든다. 𝑎 이외의 action이 선택될 때마다 𝑡은 증가하지만 행동을 한 arm의 𝑁(𝑎)를 제외한 나모지 𝑁(𝑎)들은 그렇지 않으므로 불확실성 추정치가 증가하여 다른 arm을 선택할 확률이 증가하게 된다.
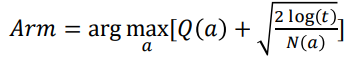
import gym_bandits
import gym
import numpy as np
import math
import random
env = gym.make("BanditTenArmedGaussian-v0")
env.action_space
#변수 초기화
#반복 수
num_rounds = 20000
#각 arm의 보상의 연속
count = np.zeros(10)
#각 arm의 보상 합계
sum_rewards = np.zeros(10)
#평균 보상인 Q value
Q = np.zeros(10)
#Upper Confidence Bound
def UCB(iters):
ucb = np.zeros(10)
#모든 arm 탐색
if iters<10:
return iters
else:
for arm in range(10):
#상한(upper_bound) 계산
upper_bound = math.sqrt((2*math.log(sum(count)))/count[arm])
#Q value에 상한 추가
ucb[arm] = Q[arm] + upper_bound
#최대 값을 가진 arm을 반환
return (np.argmax(ucb))
for i in range(num_rounds):
#UCB를 사용하여 arm 선택
arm = UCB(i)
#보상 획득
observation, reward, done, info = env.step(arm)
#해당 arm의 수를 업데이트
count[arm] += 1
#arm에서 얻은 보상 합계
sum_rewards[arm]+=reward
#arm의 평균 보상인 Q value을 계산
Q[arm] = sum_rewards[arm]/count[arm]
print('The optimal arm is {}'.format(np.argmax(Q)))The Thompson Sampling Algorithm
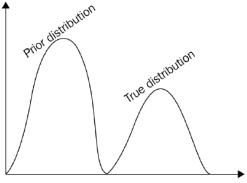
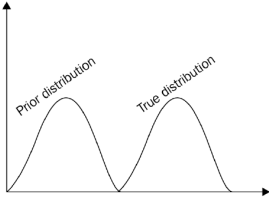
Thompson sampling (TS)은 탐색-착취(exploration-exploitation) 딜레마를 극복하기 위해 널리 사용되는 또 다른 알고리즘이다. 확률적 알고리즘이며 사전 분포를 기반으로 한다. TS 이면의 전략은 매우 간단하다. 먼저 각 k개의 arm에 대한 평균 보상에 대해 사전에 계산한다. 즉, 각 k개의 arm에서 n개의 샘플을 가져와 k 분포를 계산한다. 이러한 초기 배포는 실제 배포와 동일하지 않으므로 이를 사전 배포(prior distribution)라고 한다. Bernoulli 보상(음수 또는 양수)이 있으므로 사전 계산을 위해 베타 분포(두 개의 양수 모양 매개변수 𝛼, 𝛽로 매개변수화된 연속 확률 분포)를 사용한다.(베타 분포 값 [𝛼, 𝛽]은 간격 [0,1] 내에 있다.)
- 𝛼: 긍정적인 보상을 받은 횟수
- 𝛽: 부정적인 보상을 받은 횟수

이제 TS가 최상의 arm을 선택하는 데 어떻게 진행되는지 확인해 보자.
- 각 k 분포에서 값을 샘플링하고 이 값을 사전 평균으로 사용한다.
- 사전 평균이 가장 높은 팔을 선택하고 보상을 관찰한다.
- 관찰된 보상을 사용하여 이전 분포를 수정한다.
따라서 여러 라운드 후에 이전 분포가 실제 분포와 유사해지기 시작한다.
import gym_bandits
import gym
import numpy as np
import math
import random
env = gym.make("BanditTenArmedGaussian-v0")
env.action_space
#변수 초기화
#반복 수
num_rounds = 20000
#각 arm의 보상의 연속
count = np.zeros(10)
#각 arm의 보상 합계
sum_rewards = np.zeros(10)
#평균 보상인 Q value
Q = np.zeros(10)
#alpha와 beta 값 초기화
alpha = np.ones(10)
beta = np.ones(10)
def thompson_sampling(alpha,beta):
samples = [np.random.beta(alpha[i],beta[i])for i in range(10)]
return np.argmax(samples)
for i in range(num_rounds):
#UCB를 사용하여 arm 선택
arm = thompson_sampling(alpha,beta)
#보상 획득
observation, reward, done, info = env.step(arm)
#해당 arm의 수를 업데이트
count[arm] += 1
#arm에서 얻은 보상 합계
sum_rewards[arm]+=reward
#arm의 평균 보상인 Q value을 계산
Q[arm] = sum_rewards[arm]/count[arm]
print('The optimal arm is {}'.format(np.argmax(Q)))MAB의 응용
Bandits은 슬롯머신 플레이에만 사용되는 것이 아니다. MAB는 많은 응용 프로그램을 가지고 있다. Bandits은 AB testing를 대신하여 사용된다. AB 테스트는 일반적으로 사용되는 고전적인 테스트 방법 중 하나이다.
예를 들어, 웹사이트 방문 페이지의 두 가지 버전이 있다고 하자. 대부분의 사용자가 어떤 버전을 좋아하는지 어떻게 알 수 있을까? 유저들이 가장 좋아하는 버전을 파악하기 위해 AB 테스트를 진행한다. AB 테스트에서는 탐색을 위한 별도의 시간과 활용을 위한 별도의 시간을 할당한다. 즉, 탐사와 착취만을 위한 두 개의 서로 다른 전용 기간이 있다. 하지만 이 방법의 문제점은 많은 후회를 불러일으킨다는 것이다.
따라서 MAB를 해결하기 위해 사용하는 다양한 탐색 전략을 사용하여 후회를 최소화할 수 있다. Bandits과 별도로 완전한 착취와 탐색을 수행하는 대신 적응형 방식으로 착취와 탐색을 동시에 수행한다. Bandits는 웹 사이트 최적화, 전환율 극대화, 온라인 광고, 캠페인 등에 널리 사용된다.
단기 캠페인을 진행 중이라면 AB 테스팅을 하면 거의 대부분의 시간을 탐사와 공략에만 할애하게 되므로 이 경우 Bandits을 활용하는 것이 매우 유용할 것이다.
MAB를 사용하여 올바른 광고 배너 식별
웹사이트를 운영 중이고 동일한 광고에 대해 5개의 다른 배너가 있고 어떤 배너가 사용자를 끌어들이는지 알고 싶다. 이 문제를 Bandits 문제로 모델링할 수 있다. 이 5개의 배너가 Bandits의 다섯 arm이라고 가정하고 사용자가 광고를 클릭하면 1점을 부여하고 사용자가 광고를 클릭하지 않으면 0점을 부여한다. 일반 A/B 테스트에서는 어떤 배너가 가장 좋은지 결정하기 전에 이 다섯 가지 배너를 모두 완전히 탐색한다. 그러나 AB 테스트는 우리에게 많은 에너지와 시간을 요구된다. 대신 MAB를 사용하면 가장 많은 보상(가장 많은 클릭)을 제공할 배너를 결정하기 위해 좋은 탐색 전략이다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 열이 배너 유형이고 행이 0 또는 1인 모양으로 5*10000을 사용하여 데이터 세트를 시뮬레이션
# 즉, 사용자가 각각 광고를 클릭했는지 여부이다.
df = pd.DataFrame()
df['Banner_type_0'] = np.random.randint(0,2, 100000)
df['Banner_type_1'] = np.random.randint(0,2, 100000)
df['Banner_type_2'] = np.random.randint(0,2, 100000)
df['Banner_type_3'] = np.random.randint(0,2, 100000)
df['Banner_type_4'] = np.random.randint(0,2, 100000)
df.head(10)
#변수 초기화
#banners의 수
num_banner = 5
#반복 횟수
no_of_iterations = 100000
#선택된 배너를 저장하기 위한 목록
banner_selected = []
#배너가 선택된 횟수 계산
count = np.zeros(num_banner)
#banner의 Q value
Q = np.zeros(num_banner)
#배너로 얻은 보상의 합계
sum_rewards = np.zeros(num_banner)
#epsilon greedy policy
def epsilon_greedy(epsilon):
random_value = np.random.random()
choose_random = random_value < epsilon
if choose_random:
action = np.random.choice(num_banner)
else:
action = np.argmax(Q)
return action
for i in range(no_of_iterations):
#epsilon greedy policy을 사용하여 배너를 선택
banner = epsilon_greedy(0.5)
#보상 획득
reward = df.values[i,banner]
#해당 banner의 수를 업데이트
count[banner] += 1
#banner에서 얻은 보상 합계
sum_rewards[banner]+=reward
#banner의 평균 보상인 Q value을 계산
Q[banner] = sum_rewards[banner]/count[banner]
banner_selected.append(banner)
#가장 많은 클릭(보상)을 제공하는 배너 유형을 플롯하고 확인
sns.distplot(banner_selected)
Contextual Bandits
사용자에게 올바른 광고 배너를 추천하기 위해 bandits가 어떻게 사용되는지 살펴보았다. 그러나 배너 선호도는 사용자마다 다르다. 사용자 A는 배너 유형 1을 좋아하지만 사용자 B는 배너 유형 3을 좋아할 수 있다. 따라서 사용자 행동에 따라 광고 배너를 개인화해야 한다. 여기서 contextual bandits라는 새로운 bandit 유형이 있다.
일반적인 MAB 문제에서는 작업을 수행하고 보상을 받는다. 그러나 Contextual bandits를 사용하면 단독으로 조치를 취하는 대신 환경 상태도 취한다. 상태는 컨텍스트(context)를 보유한다. 여기에서 상태는 사용자 행동을 명시하므로 상태(사용자 행동)에 따라 최대 보상(광고 클릭)이 발생하는 조치(광고 게재)를 취한다. 따라서 사용자의 선호 행동에 따라 콘텐츠를 개인화하기 위해 contextual bandits가 널리 사용된다.
그 외에 추천 시스템에서 직면한 cold-start 문제를 해결하는 데 사용된다. cold-start 문제란 과거 이력이 없거나 거의 없는 사용자(신규 사용자)를 위한 개인화된 권장 사항으로 Netflix에서 사용자 행동에 따라 TV 프로그램의 아트워크를 개인화하기 위해 contextual bandits를 사용한다고 한다.
주섬주섬
배너 예시의 환경은 numpy와 random을 이용하여 예시로 만든 환경이다. 그러므로 항상 다른 결과가 나온다. 그렇다고, 각 배너마다 같은 확률이기에 큰 차이는 없다.
참고
나무위키나 위키백과에서 정답이 없는 내용에 대한 집단 지성은 적절한 자료가 되지 못 하지만, 과학적 수학적 내용은 집단지성으로 인해 충분히 참고할만한 내용이 나온다.
A/B 테스트 - 위키백과, 우리 모두의 백과사전
A/B 테스트는 대부분 일반적으로 모든 사용자에게 동일한 확률로 같은 변형(예를 들어, 사용자 인터페이스 요소)을 적용한다. 하지만, 같은 상황에서, 변형에 대한 응답은 이질적일 수 있다. 즉,
ko.m.wikipedia.org
'컴퓨터공학 > AI' 카테고리의 다른 글
| 강화 학습 7. Deep Q Network(DQN) (1) | 2023.05.16 |
|---|---|
| 강화 학습 6.Deep Learning Fundamentals (0) | 2023.05.09 |
| 강화 학습 4.Temporal Difference(TD) Learning (0) | 2023.04.18 |
| 강화 학습 3.Monte Carlo(MC) Methods (0) | 2023.04.04 |
| 강화 학습 2. Markov Decision Process(MDP) and Dynamic Programming(DP) (1) | 2023.03.27 |




댓글