서론
DQN(Deep Q Network)은 DRL(심층 강화 학습) 알고리즘이자 딥러닝과 강화학습을 결합한 알고리즘이다. DQN은 딥러닝 신경망을 사용하여 강화학습 에이전트를 학습시키고, 최적의 행동을 결정하는 Q-함수를 근사하는 방식을 가진다. 이전의 강화학습 알고리즘과 달리, 특징 추출기와 Q-함수 근사기를 하나의 신경망으로 통합하여 end-to-end 학습이 가능해졌다. 이를 통해 데이터 처리 속도가 향상되어 효과적인 학습이 가능해졌으며, 여러 복잡한 게임에서 인간 수준의 성능을 보이는 결과를 얻었다. 이 알고리즘을 제시한 Google의 DeepMind 연구원은 게임 화면을 입력으로 사용하여 모든 Atari(아타리) 게임을 할 때 인간 수준의 결과를 얻었다.
Deep Q Networks (DQNs)
DQN을 배우기 전 이전에 배웠던 것을 한번 상기해 보자. Q 함수는 상태-행동 가치 함수라고도 하며 상태(s)에서 행동(a)이 얼마나 좋은지 지정한다. Q 테이블이라는 테이블에 각 상태에서 가능한 모든 행동의 값을 저장하고 상태에서 최대 값을 갖는 행동을 최적의 행동으로 선택한다. Q함수 추정을 위해 오프폴리시(off-policy) 시간차(TD) 학습 알고리즘인 Q러닝을 사용하였다.
지금까지 우리는 제한된 수의 상태와 제한된 행동을 가진 환경을 보았고 최적의 Q 값을 찾기 위해 가능한 모든 상태-행동 쌍을 철저히 검색하였다. 그러나, 만약 매우 많은 상태가 있고 각 상태에서 시도할 행동이 많은 환경(e.g. 바둑)을 생각해 보자. 이러한 환경에서 각 상태는 모든 행동을 수행하려면 시간이 많이 걸린다. 이보다 더 나은 접근을 하기 위해 일부 매개변수 𝜃(Q network의 weight)를 𝑄(𝑠, 𝑎; 𝜃) ≈ 𝑄∗(𝑠, 𝑎)로 사용하여 Q 함수를 근사화한다. 가중치가 있는 신경망 𝜃을 사용하여 각 상태에서 가능한 모든 작업에 대한 Q 값을 근사화할 수 있다. 즉, 신경망을 사용하여 Q 함수를 근사화하므로 Q 네트워크(Q network)라고 부를 수 있다.
그럼 어떻게 네트워크를 훈련시키고 Q 함수를 어떻게 구할까? Q 학습 (Q learning) 업데이트 규칙을 상기해 보자.

𝑅 + 𝛾 max 𝑄(𝑠′, 𝑎')는 목표값이고 𝑄(𝑠, 𝑎)는 예측값이다. 올바른 정책을 학습하여 이러한 오류를 최소화하려고 한다. 이와 유사하게, DQN에서 손실 함수를 목표값과 예측값 사이의 제곱 차이로 정의할 수 있으며 가중치를 업데이트하여 손실을 최소화하려고 노력할 것이다.
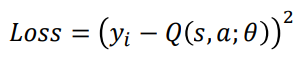
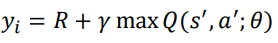
가중치를 업데이트하고 경사하강법을 통해 손실을 최소화한다.
Architecture of DQN
CNN
DQN의 첫 번째 레이어(layer)는 컨볼루션 네트워크(convolutional network)이며 네트워크에 대한 입력은 게임 화면의 프레임이 된다. 그래서, 우리는 게임 상태를 이해하기 위해 프레임을 가져와 컨볼루션 레이어(convolutional layer)에 전달한다. 또한, 프레임은 RGB 색상의 210 x 160 픽셀이므로 픽셀을 84 x 84로 다운샘플링하고 RGB 값을 그레이 스케일 값으로 변환한다. 즉, 컨볼루션 레이어는 이미지 속 오브젝트 간의 공간적 관계를 파악하여 게임 화면을 이해한다.
pooling layer를 사용하지 않는다.
풀링 레이어(pooling layer)는 이미지에서 객체의 위치를 고려하지 않고 원하는 객체가 이미지에 있는지 여부만 알고자 하는 객체 감지 또는 분류와 같은 작업을 수행할 때 유용하다.(다운 샘플링을 함) 하지만 게임 화면을 이해하기 위해서는 게임의 상태를 나타내기 때문에 위치가 중요하기에 풀링 레이어는 사용하지 않는다.
Q 값(Q value)?
하나의 게임 화면과 하나의 동작을 DQN에 입력으로 전달하면 Q 값을 제공한다. 그러나 한 상태에 많은 작업이 있기 때문에 하나의 완전한 포워드 패스(complete forward pas)가 필요하다. 또한 게임에는 각 행동에 대해 하나의 포워드 패스(forward pass)가 있는 많은 상태가 있을 것이므로 계산 비용이 많이 든다. 그래서 단순히 게임 화면만을 입력으로 전달하고 출력 레이어의 유닛 수를 게임 상태의 동작 수로 설정하여 상태에서 가능한 모든 동작에 대한 Q 값을 얻는다.
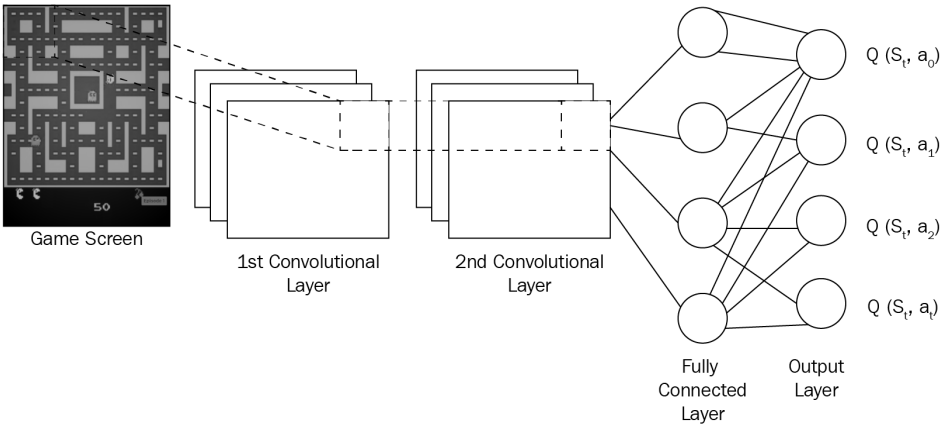
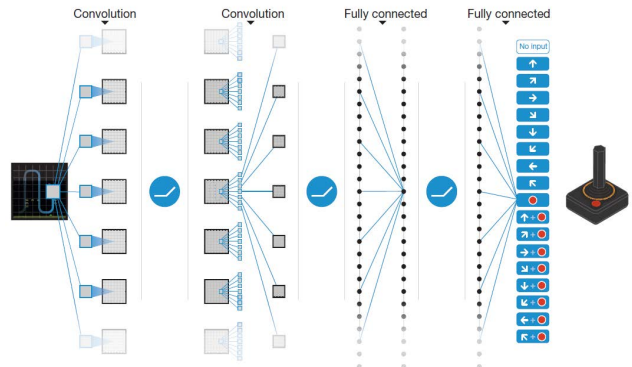
게임 상태의 Q 값을 예측하기 위해 현재 게임 화면만 사용하지 않는다. 지난 4개의 게임 화면도 고려한다. 이동하여 모든 점을 먹는 것이 목표인 Pac-Man 게임을 생각해 보자.( 좌측 이미지에 대해 간단한 설명이다.) 현재 게임 화면만 봐서는 Pac-Man이 어느 방향으로 움직이고 있는지 알 수 없다. 하지만 과거 게임 화면이 있으면 Pac-Man이 어느 방향으로 움직이는지 이해할 수 있다.
오른쪽 그림은 조이스틱으로 조종하는 게임의 DAN을 볼 수 있다. 처음에 Convloution으로 화면을 인식과 중간중간에 활성함수를 걸쳐 Fully connected를 하여 행동을 결정한다. Fully connected는 게임의 복잡도에 따라 깊이가 달라진다.
Experience Replay
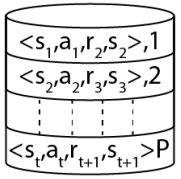
RL 환경에서 어떤 행동 𝑎을 수행을 하여 한 상태 𝑠에서 다음 상태 𝑠'로 전환하고 보상 𝑟을 받는다고 하였다. 이 전환(transition) 정보를 < 𝑠, 𝑎, 𝑟, 𝑠′ >로 리플레이 버퍼(replay buffer) 또는 경험 리플레이(experience replay)라는 버퍼에 저장한다. 이러한 전환을 에이전트의 경험이라고 한다. 경험 리플레이의 핵심 아이디어는 마지막 전환으로 교육하는 대신 리플레이 버퍼에서 샘플링된 전환으로 심층 Q 네트워크를 훈련하는 것이다. 에이전트의 경험은 한 번에 하나씩 연관되므로 리플레이 버퍼에서 훈련 샘플의 무작위 배치를 선택하면 에이전트의 경험 간의 상관관계가 줄어들고 에이전트가 다양한 경험에서 더 잘 배울 수 있다.
또한 신경망은 상관된 경험으로 과적합(overfitting)되므로 응답 버퍼에서 임의의 경험 배치를 선택하여 과적합을 줄일 수 있다. 경험을 샘플링하기 위해 균일한 샘플링을 사용할 수 있다. 리플레이 버퍼는 고정된 수의 최근 경험만 저장하므로 새 정보가 들어오면 이전 정보를 삭제하므로 경험 리플레이를 목록이 아닌 대기열로 생각할 수 있다.
Target Network
손실 함수에서 목표값과 예측값 사이의 제곱 차이를 계산한다.
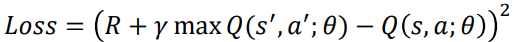
목표값과 예측값을 계산하기 위해 동일한 Q 함수를 사용하고 있다. 앞의 방정식에서 목표 Q와 예측 Q 모두에 동일한 가중치 𝜃가 사용된 것을 볼 수 있다. 동일한 네트워크에서 예측값과 목표값을 계산하므로 이 둘 사이에 많은 차이가 있을 수 있다.(gradinet가 한 번 잘 못 된 순간) 이러한 문제를 피하기 위해 목표값을 계산하기 위해 목표 네트워크(target network)라는 별도의 네트워크를 사용한다. 따라서 손실 함수는 다음과 같다.
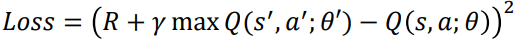
Q 값을 예측하는 데 사용되는 실제 Q 네트워크는 경사 하강법을 사용하여 𝜃의 올바른 가중치를 학습한다.(𝜃‘는 목표 가중치, 𝜃는 예측 가중치) 목표 네트워크는 여러 시간 단계 동안 고정된 다음 실제 Q 네트워크에서 가중치를 복사하여 대상 네트워크 가중치를 업데이트한다. 목표 네트워크를 잠시 동결한 다음 실제 Q 네트워크 가중치로 가중치를 업데이트하면 훈련이 안정화된다.
Clipping Rewards
보상 할당은 게임마다 다르다. 일부 게임에서는 승리 시 +1, 패배 시 -1, 아무것도 없는 경우 0과 같은 보상을 할당할 수 있지만, 다른 게임에서는 행동을 하면 +100, 다른 행동을 하면 +50과 같은 보상을 할당해야 한다. 이 문제를 피하기 위해 모든 보상을 -1과 +1로 자른다.
Understanding the Algorithm
1. 먼저 게임 화면(상태 𝑠)을 사전 처리하고 DQN에 공급하여 해당 상태에서 가능한 모든 행동의 Q 값을 반환한다.
2. 이제 𝜖-greedy 정책을 사용하여 행동을 선택한다.
3. 행동 𝑎을 선택한 후 상태 𝑠에서 이 행동을 수행하고 새로운 상태 𝑠'로 이동하여 보상을 받는다. 다음 상태 𝑠′ 는 다음 게임 화면의 전처리된 이미지이다.
4. 이 전환을 리플레이 버퍼에 < 𝑠, 𝑎, 𝑟, 𝑠′ >로 저장한다.
5. 다음으로 리플레이 버퍼에서 전환의 임의 배치를 샘플링하고 손실을 계산한다.
6. 𝐿oss = (𝑅 + 𝛾 max𝑄(𝑠′, 𝑎′; 𝜃′) - 𝑄(𝑠, 𝑎; 𝜃))^2, 목표 Q와 예측 Q 사이의 차이 제곱과 같다.
7. 이 손실을 최소화하기 위해 실제 네트워크 매개변수 𝜃와 관련하여 경사 하강법을 수행한다.
8. 매 𝑘 단계마다 실제 네트워크 가중치 𝜃를 대상 네트워크 가중치 𝜃′에 복사한다.
9. 𝑀개의 에피소드에 대해 이 단계를 반복한다.
Atari Games with Deep Q Network
Atari 게임 중 하나인 MsPacman에서 점수를 최대화하는 DAN을 만들어 보자. 이 환경에서 관찰은 모양(210, 160, 3)의 배열인 화면의 RGB 이미지이다. 각 행동은 k 프레임 기간 동안 반복적으로 수행되며, 여기서 k는 {2,3,4}에서 균일하게 샘플링된다.

import numpy as np
import gym
import tensorflow as tf
from tensorflow.contrib.layers import flatten, conv2d, fully_connected
from collections import deque, Counter
import random
from datetime import datetime
# 입력 게임 화면을 전처리하기 위해 preprocess_observation 함수 정의
# 이미지 크기를 줄이고 이미지를 그레이스케일로 변환
color = np.array([210,164,74]).mean()
def preprocess_observation(obs):
#이미지 자르기 및 크기 조정
img = obs[1:176:2,::2]
#이미지를 그레이 스케일로 변환
img = img.mean(axis=2)
#이미지 대비 향상
img[img==color] = 0
#다음으로 이미지를 -1에서 1로 정규화
img = (img - 128)/128 - 1
return img.reshape(88,80,1)
# 환경 설정
env = gym.make("MsPacman-v0")
n_outputs = env.action_space.n
# Q 네트워크를 구축하기 위해 q_network라는 함수를 정의
# Q 네트워크를 입력하고 해당 상태의 모든 작업에 대한 Q 값을 얻는다.
# fully connected layer가 이어지는 동일한 패딩을 가진 3개의 convolutional layers로 Q 네트워크를 구축
tf.reset_default_graph()
def q_network(X, name_scope):
#layers 초기화
initializer = tf.contrib.layers.variance_scaling_initializer()
with tf.variable_scope(name_scope) as scope:
#convolutional layers 초기화
layer_1 = conv2d(X, num_outputs=32, kernel_size=(8,8), stride=4, padding="SAME", weights_initializer=initializer)
tf.summary.histogram('layer_1',layer_1)
layer_2 = conv2d(layer_1, num_outputs=64, kernel_size=(4,4), stride=2, padding="SAME", weights_initializer=initializer)
tf.summary.histogram('layer_2',layer_2)
layer_3 = conv2d(layer_2, num_outputs=64, kernel_size=(3,3), stride=1, padding="SAME", weights_initializer=initializer)
tf.summary.histogram('layer_3',layer_3)
# fully connected layer에 공급하기 전에 layer_3의 결과를 평탄화
flat = flatten(layer_3)
fc = fully_connected(flat, num_outputs=128, weights_initializer=initializer)
tf.summary.histogram('fc',fc)
output = fully_connected(fc, num_outputs=n_outputs, activation_fn=None, weights_initializer=initializer)
tf.summary.histogram('output',output)
#vars는 가중치와 같은 네트워크 매개변수를 저장
vars = {v.name[len(scope.name):]: v for v in tf.get_collection(key=tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope.name)}
return vars, output
# 엡실론 그리디 정책을 수행하기 위해 epsilon_greedy라는 함수를 정의
# 영원히 탐색하고 싶지 않기 때문에 엡실론의 가치가 시간이 지남에 따라 쇠퇴하는 쇠퇴 엡실론 탐욕 정책을 사용
# 즉, 시간이 지남에 따라 우리 정책은 좋은 행동만 이용할 것입니다.
eps_min=0.05
eps_max=0.5
eps_decay_steps = 500000
def epsilon_greedy(action, step):
p = np.random.random(1).squeeze()
epsilon = max(eps_min, eps_max - (eps_max-eps_min) * step/eps_decay_steps)
if np.random.rand() < epsilon:
return np.random.randint(n_outputs)
else:
return action
# 경험을 보유하는 20000의 경험 버퍼를 초기화
# 에이전트의 모든 경험, 즉 (상태, 행동, 보상)을 경험 버퍼에 저장하고 네트워크 훈련을 위해 이 경험의 미니배치에서 샘플링
buffer_len = 20000
exp_buffer = deque(maxlen=buffer_len)
# 메모리에서 경험을 샘플링하기 위해 sampled_memories라는 함수를 정의
# 배치 크기는 메모리에서 샘플링된 경험의 수이다.
def sample_memories(batch_size):
perm_batch = np.random.permutation(len(exp_buffer))[:batch_size]
mem = np.array(exp_buffer)[perm_batch]
return mem[:,0],mem[:,1],mem[:,2],mem[:,3],mem[:,4]
# 하이퍼파라미터 정의
num_episodes = 800
batch_size = 48
input_shape = (None, 88, 80, 1)
learning_rate = 0.001
X_shape = (None, 88, 80, 1)
discount_factor = 0.97
global_step = 0
copy_steps = 100
steps_train = 4
start_steps = 2000
logdir = 'ch8_logs'
tf.reset_default_graph()
# 입력에 대한 게임 상태를 정의
X = tf.placeholder(tf.float32, shape=X_shape)
# 교육을 토글하기 위해 in_training_model이라는 부울을 정의
in_training_mode = tf.placeholder(tf.bool)
# 기본 대상 Q 네트워크를 구축
# 입력 X를 취하고 상태의 모든 작업에 대해 Q 값을 생성하는 Q 네트워크를 구축
mainQ, mainQ_outputs = q_network(X, 'mainQ')
# 목표 Q 네트워크를 구축
targetQ, targetQ_outputs = q_network(X, 'targetQ')
# 행동 값에 대한 자리 표시자 정의
X_action = tf.placeholder(tf.int32, shape=(None,))
Q_action = tf.reduce_sum(targetQ_outputs * tf.one_hot(X_action, n_outputs), axis=-1,keep_dims=True)
# 기본 Q 네트워크 매개변수를 대상 Q 네트워크에 복사
copy_op = [tf.assign(main_name, targetQ[var_name]) for var_name, main_name in mainQ.items()]
copy_target_to_main = tf.group(*copy_op)
# gradient descent optimizer를 사용하여 손실 계산 및 최적화
# 행동에 대한 자리 표시자를 정의
y = tf.placeholder(tf.float32, shape=(None,1))
# 실제 값과 예측 값의 차이인 손실을 계산
loss = tf.reduce_mean(tf.square(y - Q_action))
# loss을 최소화하기 위해 adam optimizer를 사용
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
loss_summary = tf.summary.scalar('Loss', loss)
merge_summary = tf.summary.merge_all()
file_writer = tf.summary.FileWriter(logdir, tf.get_default_graph())
# tensorflow와 그 안의 모델을 실행
with tf.Session() as sess:
init.run()
#에피소드
for i in range(num_episodes):
done = False
obs = env.reset()
epoch = 0
episodic_reward = 0
actions_counter = Counter()
episodic_loss = []
#상태가 최종 상태가 아닌 동안
while not done:
# 전처리된 게임 화면 가져오기
obs = preprocess_observation(obs)
# 게임 화면을 피드하고 각 작업에 대한 Q 값을 가져오기
actions = mainQ_outputs.eval(feed_dict={X:[obs], in_training_mode: False})
# 행동 가져오기
action = np.argmax(actions, axis =-1)
actions_counter[str(action)] += 1
#엡실론 그리디 정책을 사용하여 행동 선택
action = epsilon_greedy(action, global_step)
#행동을 수행하고 다음 상태인 next_obs로 이동하여 보상을 받는다.
next_obs, reward, done, _ = env.step(action)
#이 전환을 리플레이 버퍼에 경험으로 저장
exp_buffer.append([obs, action, preprocess_observation(next_obs), reward, done])
#특정 단계 후에 릴플레이 버퍼의 샘플로 Q 네트워크를 훈련
if global_step % steps_train == 0 and global_step > start_steps:
# 샘플 경험
o_obs, o_act, o_next_obs, o_rew, o_done = sample_memories(batch_size)
# 상태
o_obs = [x for x in o_obs]
# 다음 상태
o_next_obs = [x for x in o_next_obs]
# 다음 행동
next_act = mainQ_outputs.eval(feed_dict={X:o_next_obs, in_training_mode:False})
# 보상
y_batch = o_rew + discount_factor * np.max(next_act, axis=-1) * (1-o_done)
# 모든 요약을 병합하고 파일에 쓰기
mrg_summary = merge_summary.eval(feed_dict={X: o_obs, y:np.expand_dims(y_batch, axis=-1), X_action:o_act, in_training_mode:False})
file_writer.add_summary(mrg_summary, global_step)
# 네트워크 훈련 및 loss 계산
train_loss, _ = sess.run([loss, training_op], feed_dict={X:o_obs, y:np.expand_dims(y_batch, axis=-1), X_action:o_act, in_training_mode: True})
episodic_loss.append(train_loss)
# 일정 간격 후에 주요 Q 네트워크 가중치를 대상 Q 네트워크에 복사
if (global_step+1)%copy_steps == 0 and global_step > start_steps:
copy_target_to_main.run()
obs = next_obs
epoch += 1
global_step += 1
episodic_reward += reward
print('Epoch', epoch, 'Reward', episodic_reward,)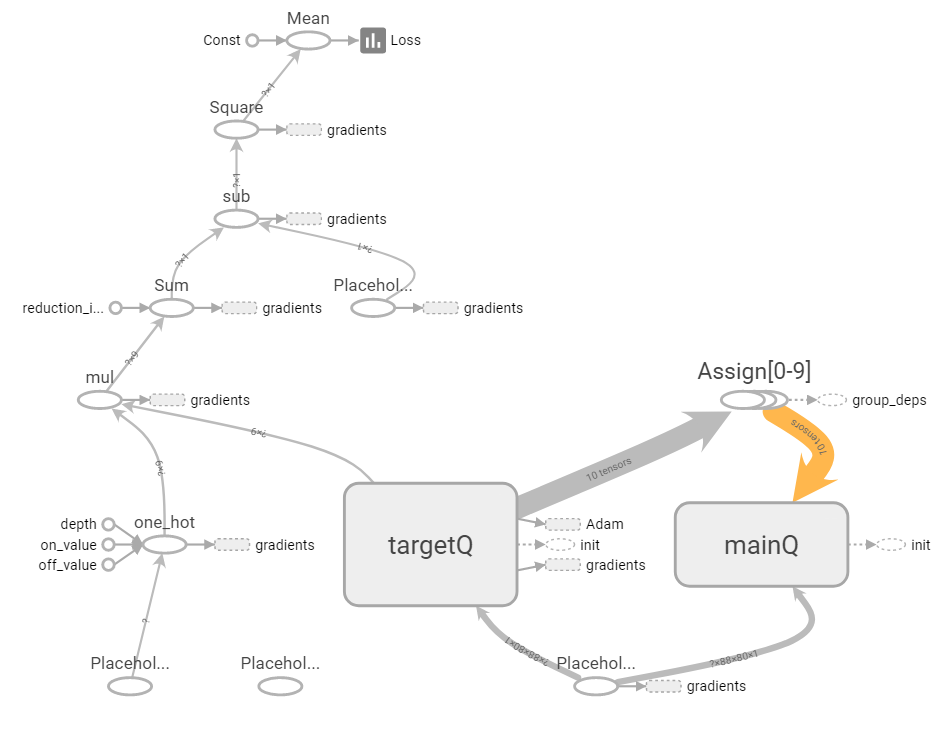
DQN Improvement
Double DQN
DQN의 문제점은 Q 값을 과대평가하는 경향이 있다는 것이다. Q 학습 방정식의 최대 연산으로 행동을 선택하고 평가하는 데 동일한 값을 사용하기 때문이다. 예를 들어, 현재 상태 s에 있고 𝑎1에서 𝑎5까지 5가지 행동이 있고 𝑎3이 최선의 행동이라고 가정해 보자. 상태 s에서 이러한 모든 행동에 대한 Q 값을 추정할 때 추정된 Q 값에는 약간의 노이즈가 있고 실제 값과 다를 수 있다. 이 노이즈로 인해 동작 𝑎2가 최적 동작 𝑎3보다 높은 값을 갖게 될 수 있다. 이제 최댓값을 가진 최선의 행동을 선택하면 최적의 행동 𝑎3 대신 차선의 행동 𝑎2를 선택하게 된다.
해결방법으로 각각 독립적으로 학습하는 두 개의 개별 Q 함수를 사용하여 이 문제를 해결할 수 있다. 하나의 Q 함수는 행동을 선택하는 데 사용되고 다른 Q 함수는 동작을 평가하는 데 사용된다. DQN의 대상 함수(target function)를 조정하여 구현할 수 있다. DQN의 대상 함수를 호출한다.
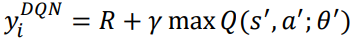
목표 함수를 다음과 같이 수정할 수 있다.
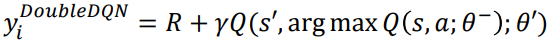
여기에 가중치가 다른 두 개의 Q 함수가 있다. 가중치가 있는 Q 함수 𝜃−로 행동을 선택하는 데 사용되고 가중치가 있는 다른 Q 함수 𝜃'는 행동을 평가하는 데 사용된다.(네트워크가 3개를 이용한다는 것이다.)
Prioritized experience replay
DQN 아키텍처에서는 훈련 샘플 간의 상관관계를 제거하기 위해 경험 재생을 사용한다. 그러나 재생 메모리에서 전환을 균일하게 샘플링하는 것은 최적의 방법이 아니다. 대신 우선순위에 따라 전환 및 샘플링의 우선순위를 지정할 수 있다. 전환의 우선순위를 지정하면 네트워크가 신속하고 효과적으로 학습하는 데 도움이 된다.
전환의 우선순위는 다음과 같이 정한다. TD 오류가 높은 전환(transition)을 우선적으로 처리한다. TD 오류가 추정 Q 값과 실제 Q 값 사이의 차이를 지정한다는 것을 알고 있다. 따라서 TD 오차가 높은 전환은 우리의 추정에서 벗어나는 전환이기 때문에 우리가 집중하고 배워야 할 전환이다. 우선 순위 지정하는 방법은 크게 두 가지로 나뉜다.
비례적 우선순위(proportional prioritization)
𝑝𝑖 = (𝛿𝑖 + 𝜖)^𝛼 여기서 𝛿𝑖는 전환 𝑖의 TD 오류이고, 𝜖는 모든 전환이 0이 아닌 우선순위를 갖도록 하는 간단한 양의 상수 값이다. 𝛼는 사용 중인 우선순위의 양을 나타낸다. 𝛼가 0이면 단순히 균일한 경우이다.
순위 기반 우선순위 지정(rank-based prioritization)
𝑝𝑖 = (1 / 𝑟ank(𝑖))^𝛼 여기서 𝑟ank(𝑖)는 전환 위치를 지정한다. 높은 TD 오류에서 낮은 TD 오류로 전환이 저장되는 리플레이 버퍼의 𝑖 위치를 지정한다. 우선순위를 계산한 후 다음 공식을 사용하여 우선순위를 확률로 변환할 수 있다.
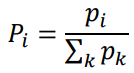
주섬주섬
Atari Games with Deep Q Network의 팩맨 코드는 공부용 코드일 뿐이며 이를 참고하여 시각적으로 보이는 코드를 짜보길 바란다. 또한 해당 코드를 작동하기 위해 앞선 강의에서 언급한 tensorflow를 설치해야한다.(pip3 install tensorflow)
참고
nature에 등재된 DQN논문이다.
강화 학습 6.Deep Learning Fundamentals
서론 딥러닝이 발전을 하면서 알파고와 같은 딥러닝과 강화학습이 결합된 형태가 생겨났기에 딥러닝의 간단한 개념에 대해 공부한 다음에 결합된 형태에 대해 알아보자. Artificial Neuron 뉴런은
jinger.tistory.com
강화 학습 4.Temporal Difference Learning
서론 Monte Carlo 방법은 에피소드 환경에만 적용된다는 단점과 에피소드가 매우 길면 가치 함수를 계산하기 위해 오랜 시간이 걸린다는 단점이 있다. 따라서 모델 없으며(model-free) 모델 역학(model d
jinger.tistory.com
'컴퓨터공학 > AI' 카테고리의 다른 글
| 강화학습 실습 코드 (0) | 2023.05.23 |
|---|---|
| 강화 학습 8. The Asynchronous Advantage Actor Critic(A3C) Network (6) | 2023.05.23 |
| 강화 학습 6.Deep Learning Fundamentals (0) | 2023.05.09 |
| 강화 학습 5.Multi-Armed Bandit (MAB)Problem (0) | 2023.04.25 |
| 강화 학습 4.Temporal Difference(TD) Learning (0) | 2023.04.18 |



댓글