서론
DQN(Deep Q Network)이 Atari 게임을 플레이하기 위해 학습을 일반화하는 데 어떻게 성공했는지 알아보았다. 그러나 많은 양의 계산 능력과 훈련 시간이 필요했다. 그래서 Google의 DeepMind는 A3C(Asynchronous Advantage Actor Critic) 알고리즘이라는 새로운 알고리즘을 도입했는데, 이 알고리즘은 계산 능력과 교육 시간이 덜 필요하다는 장점이 있다. A3C의 기본 아이디어는 병렬 학습을 위해 여러 에이전트를 사용하고 전체 경험을 집계한다는 것이다. 이 페이지에서 A3C 네트워크가 어떻게 작동하는지 알아보자.
사전 지식
Advantage Function
Q 함수가 상태 𝑠에서 에이전트가 행동 𝑎을 수행하는 것이 얼마나 좋은지 지정하고 가치 함수(value function)는 에이전트가 상태 𝑠에 있는 것이 얼마나 좋은지 지정한다는 것을 알고 있다. 이제 가치 함수와 Q 함수의 차이로 정의할 수 있는 이점 함수(advantage function)라는 새로운 함수를 알아보자.
이점 함수는 에이전트가 다른 행동에 비해 행동 𝑎을 수행하는 것이 얼마나 좋은지를 지정한다. 따라서 가치 함수는 상태가 얼마나 좋은지를 지정하고 이점 함수는 행동이 얼마나 좋은 지를 지정한다. Q 함수는 상태 𝑠에서 작업 𝑎을 수행하는 것이 얼마나 좋은지 알려준다. 즉, Q 함수를 다음과 같이 가치 함수(𝑉(𝑠))와 이점 함수(𝐴(𝑎))의 합으로 정의할 수 있다.
𝑄(𝑠, 𝑎) = 𝑉(𝑠) + 𝐴(𝑎)
Dueling Network Architecture
Dueling DQN의 구조는 끝에 있는 완전히 연결된 계층이 두 개의 스트림으로 분할된다는 점을 제외하고 본질적으로 DQN과 동일하다. 두 스트림을 살펴보면, 한 스트림은 가치 함수를 계산하고 다른 스트림은 이점 함수를 계산한다. 마지막으로 집계 층(aggregator layer)을 사용하여 이 두 스트림을 결합하고 Q 함수를 얻는다.

Q 함수 계산을 두 개의 스트림으로 나누어야 하는 이유는 다음과 같다.
- 많은 상태에서 모든 행동의 가치 추정치를 계산하는 것은 중요하지 않다. 특히 상태에 큰 행동 공간이 있는 경우에는 더욱 그렇다. 그러면 대부분의 작업이 상태에 영향을 미치지 않는다.
- 또한 중복 효과가 있는 동작이 많을 수 있다.
이 경우 dueling DQN은 기존 DQN 아키텍처보다 Q 값을 더 정확하게 추정한다.
가치 함수 스트림은 상태에 많은 수의 작업이 있고 각 작업의 가치를 추정하는 것이 실제로 중요하지 않을 때 유용하다. 이점 함수 스트림은 네트워크가 다른 것보다 선호되는 행동을 결정해야 할 때 유용하다. 그림에서도 가치 함수에서 해당 상태에 대한 뉴런만 존재하지만, 이점 함수 스트림에서는 선호되는 모든 행동을 보여주기에 많은 뉴런을 볼 수 있다. 집계 층은 이 두 스트림의 값을 결합하고 Q 함수를 생성한다. 따라서 Dueling Network는 표준 DQN 아키텍처보다 더 효과적이고 견고하다.
Policy Gradient Methods
모든 강화 알고리즘에서의 목표는 보상을 최대화할 수 있도록 올바른 정책을 찾는 것이다. 지금까지 모든 방법은 에이전트들이 행동-가치 방법(Action-Value Methods)를 배운 다음 추정된 행동 가치에 따라 행동을 선택했다. 여기서 정책은 행동 가치 추정치에 의존한다. 그럼 Q 함수를 사용하지 않고 최적의 정책을 직접 찾을 수 없을까라는 생각에 등장한 것이 정책 기울기 방법(Policy Gradient Methods)이다. 정책 기울기 방법은 가치 함수의 도움 없이도 행동을 선택할 수 있는 정책을 최적화하는 방법이다. 가치 함수는 정책 매개 변수를 학습하는 데에는 여전히 사용될 수 있지만, 행동 선택에는 필요하지 않는다. 매개 변수화된 정책(𝜋(a | s; θ))은 매개 변수 θ에 따라 시간 t에서 상태 s에 대해 행동 a를 선택하는 확률을 나타낸다.
𝜋(𝑎, 𝑠; 𝜃) = Pr{𝐴𝑡 = 𝑎|𝑆𝑡 = 𝑠, 𝜃𝑡 = 𝜃}
정책 기울기 방법은 일부 스칼라 성능 지표 J(θ)의 기울기를 기반으로 정책 매개 변수를 학습하는 방법을 고려한다. 이러한 방법은 성능을 극대화하기 위해 업데이트 근사를 사용하며 다음과 같다.
θ(t+1) = θ(t) + α∇J(θ(t))
여기서, θ(t)는 시간 단계 t에서의 정책 매개 변수를 나타내며, α는 학습률을 의미하고, ∇J(θ(t))는 성능 지표에 대한 정책 매개 변수의 기울기를 나타낸다.
정책 기울기 방법은 정책과 가치 함수 모두를 근사화하는 방법으로 액터-크리틱(Actor-Critic) 방법이라고도 불린다. 액터는 학습된 정책을 의미하며, 크리틱은 일반적으로 상태 가치(state-value) 함수를 나타낸다.
Monte Carlo Policy Gradient
Monte Carlo Policy Gradient(MCPG)은 정책 기울기 방법 중 하나로, 강화학습에서 사용되는 알고리즘이다. 이 방법은 몬테카를로(Monte Carlo) 샘플링을 활용하여 정책의 기울기를 추정하고 업데이트한다. MCPG은 기울기 추정에 몬테카를로 샘플링을 사용하므로 에피소드 단위로 업데이트가 이루어진다. 이를 통해 큰 규모의 강화학습 문제에서도 적용이 가능하며, 정책의 파라미터 공간에서 지역 최적해에 빠지지 않고 전역 최적해를 찾을 수 있다.
∇ ln 𝑥 = ∇𝑥/𝑥이기 때문에 ∇𝜋(𝐴𝑡|𝑆𝑡,𝜃) / 𝜋(𝐴𝑡|𝑆𝑡,𝜃) 대신에 ∇ ln 𝜋(𝐴𝑡|𝑆𝑡, 𝜃) (자격 벡터, eligibility vector)을 사용한다. 알고리즘에서 정책 매개변수화가 나타나는 유일한 위치라는 점에 유의 바란다.
REINFORCE with Baseline
REINFORCE with Baseline은 Policy Gradient 알고리즘 중 하나로, 가치 함수의 기준선(baseline)을 추가하여 학습의 안정성과 효율성을 향상하는 방법이다. REINFORCE 알고리즘은 몬테카를로 샘플링을 사용하여 정책 기울기를 추정하고, 이를 통해 정책을 업데이트한다. 그러나 REINFORCE 알고리즘은 샘플링된 에피소드의 반환값에 크게 의존하므로, 분산이 크고 학습이 불안정할 수 있다. REINFORCE with Baseline은 이러한 문제를 해결하기 위해 가치 함수의 기준선을 도입하였다. 기준선은 에피소드의 반환값과 비교하여 장기적인 보상의 차이를 계산하는 역할을 한다. 이를 통해 정책 기울기의 분산을 줄이고 학습을 안정화할 수 있다. REINFORCE with Baseline은 정책 기울기 알고리즘에서 보다 안정적인 학습을 이끌어내며, 분산을 감소시켜 더 빠른 학습을 가능하게 한다. 기준선은 보상의 기댓값을 예측하는 데 도움을 주는데, 일반적으로 가치 함수를 사용하여 추정한다.
정책 기울기는 행동 값과 임의의 기준선 𝑏(𝑠)의 비교를 포함하도록 일반화할 수 있다. 기준선에 대한 자연스러운 선택 중 하나는 상태 값 𝑣^(𝑆𝑡, 𝐰)의 추정치이다. 여기서 𝐰 ∈ R𝑑는 강화 학습 방법 중 하나로 학습된 가중치 벡터이다.
Actor-Critic Methods
REINFORCE-with-baseline 방법은 정책과 상태 가치 함수를 모두 학습하지만 상태 가치 함수는 critic가 아닌 기준선으로만 사용되기 때문에 actor–critic 방법으로 간주하지 않는다. Actor-Critic 방법은 정책(policy)과 가치 함수(value function)를 모두 근사화(approximation)하여 학습하는 방법이다. Actor-Critic 메서드는 두 개의 주요 구성 요소로 구성된다.
- Actor (액터): 액터는 정책을 학습하는 역할을 담당한다. 정책은 상태(state)를 입력으로 받아서 행동(action)을 선택하는 함수이다. 액터는 현재 상태에서 행동을 선택하고, 선택한 행동을 환경에 적용하여 다음 상태로 전환한다.
- Critic (크리틱): 크리틱은 가치 함수를 학습하는 역할을 담당한다. 가치 함수는 상태-행동 쌍에 대한 값 또는 예상 반환(Return)을 추정하는 함수이다. 크리틱은 액터가 선택한 행동의 가치를 평가하고, 이를 통해 액터의 학습에 도움을 준다.
Actor-Critic 메서드는 정책 기울기 방법(policy gradient)과 가치 기반 학습(value-based learning)의 장점을 결합하여 효과적인 학습을 수행할 수 있다. 액터는 탐험과 정책 개선을 담당하고, 크리틱은 가치 평가를 수행하여 액터의 학습에 도움을 주는 역할을 한다. 이를 통해 안정적이고 효율적인 강화학습을 할 수 있다.
A3C
The Asynchronous Advantage Actor Critic (A3C)
앞서 언급한 장점 외에도 다른 알고리즘에 비해 정확도가 우수하고 연속 및 불연속 행동 공간 모두에서 잘 작동한다. 이러한 장점들 덕분에 A3C 네트워크가 돌풍을 일으키며 DQN을 장악했다. 여러 에이전트를 사용하며 각 에이전트는 실제 환경의 사본에서 서로 다른 탐색 정책으로 병렬 학습한다. 그런 다음 이러한 에이전트에서 얻은 경험은 글로벌 에이전트에 집계된다. 글로벌 에이전트는 마스터 네트워크 또는 글로벌 네트워크라고도 하며 다른 에이전트는 워커라고도 한다. 이제 A3C가 어떻게 작동하고 DQN 알고리즘과 어떻게 다른지 자세히 살펴보자.
The Three As
Asynchronous(비동기식)
DQN과 같이 최적의 정책을 배우려고 시도하는 단일 에이전트 대신 환경과 상호 작용하는 여러 에이전트가 있다. 동시에 환경과 상호 작용하는 여러 에이전트가 있으므로 각 에이전트가 자신의 환경 복사본과 상호 작용할 수 있도록 모든 에이전트에 환경 복사본을 제공한다. 따라서 이러한 모든 다중 에이전트를 작업자 에이전트라고 하며 모든 에이전트가 보고하는 글로벌 네트워크라는 별도의 에이전트가 있다.(글로벌 네트워크는 학습을 집계한다.)
Advantage(이점)
이점 함수는 Q 함수와 가치 함수의 차이로 정의할 수 있다. Q 함수가 상태에서 동작이 얼마나 좋은지를 지정하고 가치 함수가 상태가 얼마나 좋은지를 지정한다는 것을 알고 있다. 즉, 직관적으로 에이전트가 상태 𝑠에서 행동 𝑎을 수행하는 것이 다른 모든 행동과 비교하여 얼마나 좋은지 알려준다.
Actor Critic
아키텍처에는 Actor와 Critic 두 가지 유형의 네트워크가 있다. 액터의 역할은 정책을 배우는 것이며, 크리틱의 역할은 액터가 배운 정책이 얼마나 좋은지 평가하는 것이다.
The Architecture of A3C
앞서 논의한 바와 같이 각각 자체 환경 사본과 상호 작용하는 여러 작업자 에이전트가 있음을 알 수 있다. 그런 다음 에이전트는 정책을 학습하고 정책 손실의 기울기를 계산하고 기울기를 글로벌 네트워크에 업데이트한다. 이 글로벌 네트워크는 모든 에이전트에 의해 동시에 업데이트된다. A3C의 장점 중 하나는 DQN과 달리 여기에서 경험 재생 메모리(experience replay memory)를 사용하지 않는다는 것이다.
환경과 상호 작용하고 정보를 글로벌 네트워크에 집계하는 여러 에이전트가 있으므로 경험 간에 상관관계가 없다. 경험 재생은 모든 경험을 담고 있는 메모리가 많이 필요하다. 그러나 A3C는 경험 재생 메모리를 필요로 하지 않기 때문에 저장 공간과 계산 시간이 줄어들 것이다.
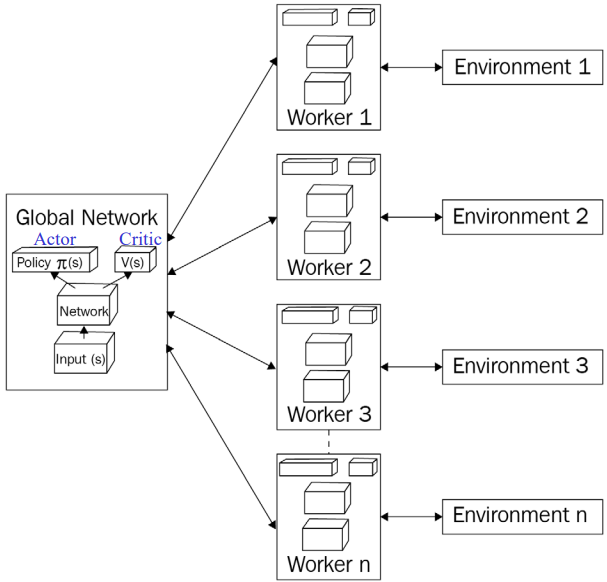
How A3C Works
A3C(Aynchronous Advantage Actor-Critic)는 다중 CPU 스레드를 사용하여 병렬로 학습을 수행하는 방법이다. 각각의 에이전트는 서로 다른 탐험 정책을 사용하며 환경과 상호작용하여 최적의 정책을 학습한다. 전역 네트워크를 초기화하고 에이전트는 환경과 상호작용하며 학습을 진행한다. 각 에이전트는 가치와 정책 손실을 계산하고 이를 전역 네트워크의 그래디언트로 업데이트한다. 이러한 과정을 반복하여 전체적인 학습이 이루어진다. 이는 더 이상 경험 재생에 의존하지 않으므로 Sarsa 및 Actor-Critic과 같은 정책 강화 학습 방법을 사용하여 안정적인 방식으로 NN을 훈련할 수 있다.
또한, A3C에서 중요한 개념은 Advantage(이점) 함수이다. 어드밴티지는 Q 함수와 가치 함수의 차이로 정의된다. A3C에서는 Q 값을 직접적으로 계산하지 않고 할인된 리턴(discounted return)을 Q 값의 추정값으로 사용한다. 이를 통해 이점 함수를 할인된 리턴과 가치 함수의 차이로 계산할 수 있다.
𝐴(𝑠, 𝑎) = 𝑄(𝑠, 𝑎) - 𝑉(𝑠)
A3C에서는 가치 손실과 정책 손실을 사용하여 네트워크를 학습한다. 실제로 A3C에서 Q 값을 직접 계산하지 않기 때문에 할인된 수익을 Q 값의 추정치로 사용한다.
𝑅 = 𝑟𝑛 + 𝛾𝑟𝑛−1 + 𝛾^2𝑟𝑛−2
다음과 같이 Q 함수를 할인된 수익 R로 바꿀 수 있다.
𝐴(𝑠, 𝑎) = 𝑅 - 𝑉(𝑠)
가치 손실을 할인된 수익과 상태 가치 간의 제곱 차이로 쓸 수 있다.
𝑉alueLoss 𝐿(𝑣) = ∑(𝑅 − 𝑉(𝑠)) ^ 2
정책 손실은 다음과 같이 정의할 수 있다.
𝑃oliceLoss 𝐿(𝑝) = 𝐿og(𝜋(𝑠)) ∗ 𝐴(𝑠) + 𝛽𝐻(𝜋)
정책 손실에는 엔트로피 항(𝐻(𝜋))도 포함되어 있다. 엔트로피는 정책의 탐험을 보장하기 위해 사용되며, 정책의 확률 분포의 분산을 나타낸다. 엔트로피를 손실 함수에 추가함으로써 에이전트가 더 많은 탐험을 수행하고 국소 최적점에 갇히지 않도록 도움을 준다.
주섬주섬
A3C의 예로 Driving Up a Mountain이 있다. 요청 시 여태 강화학습 예시에 쓰인 코드들을 정리한 블로그 비밀번호를 알려주겠다.
참고
강화 학습 7. Deep Q Network(DQN)
서론 DQN(Deep Q Network)은 DRL(심층 강화 학습) 알고리즘이자 딥러닝과 강화학습을 결합한 알고리즘이다. DQN은 딥러닝 신경망을 사용하여 강화학습 에이전트를 학습시키고, 최적의 행동을 결정하는
jinger.tistory.com
강화 학습 3.Monte Carlo Methods
서론 MDP에서 최적의 정책을 찾기 위해 DP를 사용하였고, DP를 사용하려면 transition과 reward probabilities를 알고 있는 model dynamics에서 가능하였다. 하지만 model dynamics을 모르는 경우도 있을 것이다. 이
jinger.tistory.com
'컴퓨터공학 > AI' 카테고리의 다른 글
| 기계 학습 1.기본 개념 (0) | 2023.09.13 |
|---|---|
| 강화학습 실습 코드 (0) | 2023.05.23 |
| 강화 학습 7. Deep Q Network(DQN) (1) | 2023.05.16 |
| 강화 학습 6.Deep Learning Fundamentals (0) | 2023.05.09 |
| 강화 학습 5.Multi-Armed Bandit (MAB)Problem (0) | 2023.04.25 |



댓글