서론
딥러닝에서 복잡한 문제를 해결하기 위해 깊은 신경망(DNN)을 사용할 때 발생하는 주요 문제들이 있다. 첫째, Vanishing and Exploding Gradients Problem은 깊은 네트워크에서 역전파 과정에서 그래디언트가 점차 작아지거나 커지는 문제이다. 둘째, 부족한 훈련 데이터와 비용 문제는 많은 레이어와 파라미터를 가진 네트워크를 훈련시키기 위해 충분한 양의 레이블이 지정된 데이터가 필요하다. 셋째, 훈련 속도의 문제는 대규모 네트워크의 훈련이 느릴 수 있다. 마지막으로, 과적합 위험은 수백만 개의 파라미터를 가진 모델이 훈련 데이터 부족이나 노이즈로 인해 과적합될 위험이 크다. 이 문제들의 해결책을 알아보고 이러한 기술들을 통해 복잡한 문제에 대한 딥러닝 모델을 효과적으로 훈련시킬 수 있다.
기울기 소실/폭주 문제(The Vanishing/Exploding Gradients Problems)

Vanishing(소실) gradients problem은 역전파 알고리즘이 하위 레이어로 진행됨에 따라 그래디언트가 점차 작아지는 현상으로, 이로 인해 하위 레이어의 연결 가중치가 거의 변경되지 않아 훈련이 좋은 해결책으로 수렴하지 않는 문제이다. 반면, Exploding(폭주) gradients problem은 그래디언트가 커져서 레이어의 가중치 업데이트가 엄청나게 커지고 알고리즘이 발산하는 현상이 있다. 이러한 문제들로 인해 딥 뉴런 네트워크는 다양한 속도로 학습하게 되는데, 이는 불안정한 그래디언트로 이어진다.
이 문제들은 과거에 관측되었으며, 특히 로지스틱 시그모이드 활성화 함수와 해당 시기에 널리 사용된 가중치 초기화 기술의 조합에서 발생하는 것으로 확인되었다. 이 조합은 각 레이어의 출력 분산이 입력의 분산보다 훨씬 크다는 것을 보여주었다. 네트워크를 진행함에 따라 분산은 계속 증가하고, 활성화 함수가 상위 레이어에서 포화되면서 문제가 더 악화되었다. 이 문제는 로지스틱 함수의 평균이 0.5가 아닌 0이기 때문에 더욱 악화되었다.
이러한 문제를 해결하기 위해 Glorot와 Bengio는 새로운 초기화 기술을 제안했는데, 이를 통해 각 레이어의 출력 분산과 입력 분산을 비슷하게 유지하도록 했다. 이를 통해 그래디언트 소실 및 폭주 문제를 완화하고 깊은 신경망에서 안정적인 훈련을 가능케 했다.
Glorot and He Initialization


| 초기화 | 활성 함수 | o²(Normal) |
| Glorot | None, tanh, logistic, softmax | 1 / 𝑓𝑎𝑛avg |
| He | ReLU & variants | 2 / 𝑓𝑎𝑛in |
| LeCun | SELU | 1 / 𝑓𝑎𝑛in |
2010년 Glorot와 Bengio가 제안한 초기화 기술인 Glorot 초기화는 불안정한 그래디언트 문제를 크게 완화하는 방법 중 하나이다. 이들은 신호가 정상적으로 양방향으로 흐르도록 해야 한다고 강조하며 신호가 소멸되거나 폭발하여 포화되지 않도록 해야 한다고 설명했다. 즉, 신호가 올바르게 흐르려면 각 레이어의 출력 분산이 입력 분산과 동일해야 하며, 그래디언트는 역방향으로 레이어를 통과한 후에도 동일한 분산을 가져야 한다. 그러나 레이어에 입력과 뉴런의 수가 동일하지 않으면 두 가지 모두를 보장하는 것은 불가능하다. 이러한 사실에도 불구하고 Glorot 초기화는 실제로 매우 효과적으로 작동하는 좋은 절충안이다.
레이어의 연결 가중치는 Glorot 초기화 또는 Xavier 초기화라고도 불리는 이 방법에 따라 무작위로 초기화되어야 한다. 여기서 𝑓𝑎𝑛in은 레이어의 입력 수이고, 𝑓𝑎𝑛out은 레이어의 뉴런 수이다. Glorot 초기화를 사용하면 훈련 속도를 상당히 높일 수 있으며, 이는 딥 러닝의 성공에 기여한 트릭 중 하나이다. 다양한 활성화 함수에 대해 유사한 전략을 제안하는 논문들도 있다. 이러한 전략은 분산의 크기 및 𝑓𝑎𝑛avg 또는 𝑓𝑎𝑛in에 따라 다를 뿐이다.
keras.layers.Dense(10, activation="relu", kernel_initializer="he_normal")Keras는 기본적으로 균등 분포를 사용하는 Glorot 초기화를 사용한다. 레이어를 생성할 때 kernel_initializer 매개변수를 "he_uniform" 또는 "he_normal"로 설정하여 He 초기화로 변경할 수 있다.
Nonsaturating Activation Functions
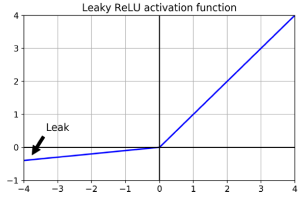
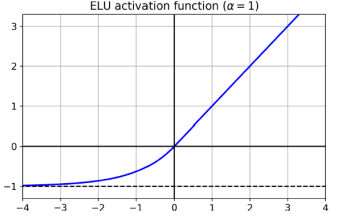
layer = keras.layers.Dense(10, activation="selu", kernel_initialier="lecun_normal") 2010년 Glorot와 Bengio의 논문에서 얻은 통찰 중 하나는 불안정한 그래디언트와 관련하여 활성화 함수의 부적절한 선택이 일부 문제의 원인 중 하나였다는 것이다. 다른 활성화 함수(시그모이드 활성화 함수가 아닌)가 심층 신경망에서 훨씬 더 잘 작동하는데, 특히 ReLU(Recitified Linear Unit) 활성화 함수는 양수 값에 대해 포화되지 않고(계산이 빠르기 때문에) 특히 잘 동작한다. 그러나 ReLU 활성화 함수는 완벽하지 않는다. "죽은 ReLU(dying ReLUs)"라고 알려진 문제가 있어서 훈련 중에 일부 뉴런이 사실상 "죽게"되어 0 이외의 출력을 하지 않게 된다. 특히 큰 학습률을 사용한 경우에는 네트워크의 뉴런 중 절반이 죽어있을 수 있다.
이 문제를 해결하기 위해 ReLU 함수의 변형 중 하나인 leaky ReLU와 같은 함수를 사용할 수 있다. leaky ReLU는 𝑧 < 0인 경우의 함수 기울기를 나타내는 하이퍼파라미터 𝛼로 𝑧보다 작은 경우에 𝛼를 기울기로 사용하며, 일반적으로 0.01로 설정된다. 이 작은 기울기는 leaky ReLU가 결코 "죽지" 않도록 보장하며, 오랜 시간 동안 비활성화 상태에 있을 수 있지만 결국 깨어날 기회를 가진다.
2015년에 Djork-Arne Clevert 등은 ReLU의 변형인 Exponential Linear Unit (ELU)라는 새로운 활성화 함수를 제안했으며, 이 함수는 실험에서 모든 ReLU 변형을 능가했다. 훈련 시간이 줄어들었고 신경망은 테스트 세트에서 더 좋은 성능을 보였다. 2017년에 Gunter Klambauer 등은 Scaled ELU(SELU) 활성화 함수를 소개되었다. 이름에서 알 수 있듯이 SELU는 ELU 활성화 함수의 변형이다. 만약 모든 은닉 레이어가 SELU 활성화 함수를 사용한다면 네트워크는 자가 정규화(self-normalize)된다. 이는 각 레이어의 출력이 훈련 중에 평균 0 및 표준 편차 1을 유지하려고 하기 때문에 그래디언트 소실/폭발 문제를 해결한다. 자가 정규화가 발생하려면 몇 가지 조건이 있습니다. 입력 특성은 표준화(평균 0 및 표준 편차 1)되어야 하며, 모든 은닉 레이어의 가중치는 LeCun 정규 초기화로 초기화되어야 한다. 또한 네트워크 아키텍처는 순차적이어야 한다. SELU를 순차적이지 않은 아키텍처(예: 순환 신경망 또는 스킵 연결이 있는 네트워크)에 사용하면 자가 정규화가 보장되지 않을 수 있다.
Batch Normalization
Batch Normalization (BN)은 2015년 Sergey Ioffe와 Christian Szegedy가 제안한 기법으로, 심층 신경망에서 발생하는 그래디언트 소실 및 폭발 문제를 완화하는 데 사용된다. BN은 각 은닉 레이어의 활성화 함수 전후에 연산을 추가함으로써 이 문제들을 다룬다. 이 연산은 각 입력을 제로 중심화하고 정규화한 후에 두 개의 새로운 매개변수 벡터를 사용하여 결과를 스케일링하고 이동시킨다.

입력의 평균과 표준 편차를 추정하기 위해 현재 미니 배치에 대한 입력의 평균과 표준 편차를 계산한다. 훈련 중에 BN은 입력을 표준화한 다음 다시 스케일링하고 이동시킨다. 그러나 테스트 시에는 각 입력의 평균과 표준 편차를 계산할 방법이 없을 수 있다. 이를 해결하기 위해 일부 구현은 훈련 중에 해당 레이어의 입력 평균과 표준 편차의 지수 이동 평균을 사용하여 이러한 "최종" 통계를 추정한다.
BN은 심층 신경망의 그래디언트 소실 문제를 감소시켜주어 훈련 초기에는 tanh나 로지스틱과 같은 포화 활성화 함수를 사용할 수 있다. 또한 가중치 초기화에 대한 민감성이 감소하고, 훈련 속도를 크게 향상시켰다. BN은 자체적으로 정규화 역할을 하며, 다른 정규화 기법(예: 드롭아웃)의 필요성을 감소시켰다.
model = keras.model.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.BatchNormalization(),
keras.layers.Dense(300, kernel_initializer="he_normal", use_bias=False),
keras.layers.BatchNormalization(),
keras.layers.Activation("elu"),
keras.layers.Dense(100, kernel_initializer="he_normal", use_bias=False),
keras.layers.BatchNormalization(),
keras.layers.Activation("elu"),
keras.layers.Dense(10, activation="softmax")
])
optimizer = keras.optimizers.SGD(clopvalue=1.0)
model.compile(loss="mse", optimizer=optimizer)Keras에서는 BN을 구현하기 위해 각 은닉 레이어의 활성화 함수 전후에 BatchNormalization 레이어를 추가하면 된다. 이때 각 BN 레이어당 4개의 매개변수가 추가되며, 이 중 마지막 두 매개변수는 이동 평균을 나타낸다. BN 레이어를 활성화 함수 앞에 추가하는 것이 더 좋다는 주장도 있으나, 작업에 따라 다를 수 있습니다. 이 경우에는 이전 레이어의 편향 항을 제거해야 한다.
Gradient Clipping
폭발 그래디언트 문제를 완화하기 위한 또 다른 인기 있는 기술은 역전파 중에 그래디언트를 어떤 임계값을 초과하지 않도록 자르는 것이다. 이를 Gradient Clipping이라고 한다. 이 기술은 주로 순환 신경망(Recurrent Neural Networks, RNNs)에서 사용되며 Batch Normalization은 RNNs에서 사용하기 어려운 경우가 많다. (다른 유형의 네트워크에 대해서는 보통 BN이 충분하다.) Keras에서 Gradient Clipping을 구현하는 것은 옵티마이저를 생성할 때 clipvalue 또는 clipnorm 인자를 설정하는 것뿐입니다. 아래와 같이 설정할 수 있다. 이 옵티마이저는 그래디언트 벡터의 각 구성 요소를 -1.0에서 1.0 사이의 값으로 자를 것이다.
사전 학습된 레이어 재사용(Reusing Pretrained Layers)
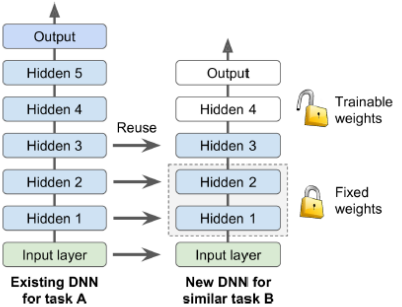
신경망을 처음부터 훈련하는 것은 일반적으로 좋은 생각이 아니다. 대신 유사한 작업을 수행하는 기존 신경망을 찾아 이 네트워크의 하위 레이어를 재사용해야 한다. 이 기술을 전이 학습(Transfer Learning)이라고 한다. 이를 통해 훈련 시간이 상당히 단축되고 훈련 데이터가 훨씬 적게 필요하다.
Keras에서 전이 학습(Transfer Learning)
전이 학습(Transfer Learning)은 기존에 훈련된 모델의 일부 레이어를 새로운 모델에 재사용하여 훈련 시간을 단축하고 적은 양의 데이터로도 좋은 성능을 얻을 수 있는 기술이다. 이를 Keras를 통해 구현하는 방법은 다음과 같다.
- 먼저, 예를 들어 Fashion MNIST 데이터셋에서 셔츠와 샌달을 제외한 여덟 가지 클래스로 모델 A를 훈련했다고 가정하자. 모델 A는 상당히 좋은 성능을 얻었다(정확도 > 90%).
- 이제 다른 작업에 착수하려고 하는데, 여러분은 샌달과 셔츠의 이미지를 가지고 이진 분류기(양성=셔츠, 음성=샌달)를 훈련하려고 한다. 레이블이 달린 이미지는 200장뿐이다. 이 새로운 작업을 위해 모델 B를 만들었고, 모델 A와 동일한 구조를 가지고 있지만 조금 더 높은 정확도(97.2%)를 기대했다.
- 모델 A를 로드하고 해당 모델의 레이어를 기반으로 새로운 모델을 만든다. 모델 A의 출력 레이어를 제외한 모든 레이어를 재사용한다. 일반적으로 기존 모델의 출력 레이어는 새 작업에 거의 유용하지 않으며 올바른 출력 수조차 가지지 않을 수 있다.
- 이제 새로운 출력 레이어를 초기화하고, 처음 몇 번의 에포크 동안 재사용된 레이어를 동결하여 새 레이어가 합리적인 가중치를 학습할 시간을 주는 것이 좋다.
- 이제 새로운 모델(model_B_on_A)은 모델 A에서 가져온 레이어를 재사용하면서, 새로운 작업에 맞게 훈련되었다. 처음 몇 번의 에포크 동안은 새 레이어만 훈련되고, 나머지 에포크 동안에는 모든 레이어가 훈련된다. 이를 통해 효과적으로 전이 학습을 수행할 수 있다.
model_A = keras.models.load_model("my_model_A.h5")
model_B_on_A = keras.models.Sequential(model_A.layers[:-1])
model_B_on_A.add(keras.layers.Dense(1, activation="sigmoid"))
model_A_clone = keras.models.clone_model(model_A)
model_A_clone.set_weights(model_A.get_weights())
for layer in model_B_on_A.layers[:-1]:
layer.trainable = False
model_B_on_A.compile(loss="binary_crossentropy", optimizer="sgd", metrics=["accuracy"])
history = model_B_on_A.fit(X_train_B, y_trrain_B, epochs=4, validation_data = (X_valid_B, y_valid_B))
for layer in model_B_on_A.layers[:-1]:
layer.trainable = True
optimizer = keras.optimizers.SGD(lr=1e-4) # 디폴트 1e-2
model_B_on_A.compile(loss="binary_crossentropy", optimizer=optimizer, metrics=["accuracy"])
history = model_B_on_A.fit(X_train_B, y_train_B, epochs=16, validation_data=(X_valid_B, y_valid_B))Unsupervised Pretraining
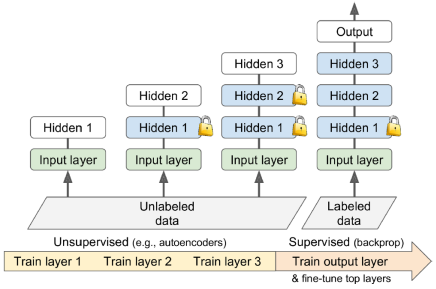
충분한 양의 라벨이 없는 훈련 데이터를 수집할 수 있다면, 비지도 학습 모델인 오토인코더 또는 생성적 적대 신경망(GAN)과 같은 모델을 훈련하는 것을 시도할 수 있다. 그런 다음 오토인코더의 하위 레이어 또는 GAN의 판별자의 하위 레이어를 재사용하고, 이에 새로운 작업을 위한 출력 레이어를 추가한 후 지도 학습(라벨이 지정된 훈련 예제를 사용한 학습)을 통해 최종 네트워크를 세밀하게 조정(finetune)할 수 있다.
Faster Optimizers
Momentum Optimization

모멘텀 최적화는 경사 하강법과 비교하여 이전 그래디언트에 큰 관심을 두는 최적화 방법이다. 경사 하강법이 경사면을 따라 작고 규칙적인 단계를 내려가는 반면, 모멘텀 최적화는 관성 벡터 m에 이전 그래디언트를 빼고 학습률 η로 곱한 후 이 모멘텀 벡터를 가중치에 더하여 업데이트한다.
모멘텀 최적화는 이전에 계산된 그래디언트가 거의 없는 플래토 현상(gradient가 거의 0인 지점)에서 빠르게 벗어날 수 있다. 경사 하강법은 가파른 경사면을 빠르게 내려가지만 계곡에 도달하는 데 많은 시간이 걸리는 반면, 모멘텀 최적화는 계곡을 빠르게 따라 내려가면서 점점 빨라져 최적점에 도달한다.
optimizer = keras.optimizers.SGD(lr=0.001, momentum=0.9)Keras에서는 위와 같이 모멘텀 최적화를 설정할 수 있다.
Nesterov Accelerated Gradient (NAG)


Nesterov Accelerated Gradient (NAG)는 모멘텀 최적화의 작은 변형 중 하나로, 거의 항상 기본적인 모멘텀 최적화보다 빠르다. 이 방법은 비용 함수의 그래디언트를 로컬 위치 θ가 아닌 모멘텀 방향인 θ + βm에서 약간 앞서 측정한다. 일반적으로 모멘텀 벡터는 올바른 방향(즉, 최적점 방향)을 가리키기 때문에 원래 위치에서의 그래디언트보다 조금 더 앞서 위치에서의 그래디언트를 사용하는 것이 더 정확할 수 있다. 주의할 점은 모멘텀이 가중치를 계곡을 향해 밀어내면, ∇1은 계곡을 더 넓게 향해 밀어내지만, ∇2는 다시 계곡의 바닥 쪽으로 밀어냅니다. 이로써 진동을 감소시켜 NAG는 빨리 수렴하게 된다.
optimizer = keras.optimizer.SGD(lr=0.001, momentum=0.9, nesterov = True)Keras에서는 다음과 같이 Nesterov 모멘텀 최적화를 설정할 수 있다.
AdaGrad (Adaptive Subgradient)




AdaGrad(적응형 서브그래디언트) 알고리즘은 경사 하강법이 가파른 차원을 따라 빠르게 내려가는 동시에 길게 늘어진 계곡을 따라 느리게 내려가도록 보정할 수 있도록 하는 것을 고려한다. 이 알고리즘은 기울기 벡터를 가파른 차원을 따라 더 빠르게 감소시키는 방식으로 보정을 수행한다.
첫 번째 단계에서는 기울기의 제곱을 벡터 s에 누적시킨다. 이는 각 차원의 기울기에 대한 편도 함수의 제곱을 누적하는 것으로, 비용 함수가 i번째 차원을 따라 가팔라질수록 벡터 s의 각 요소가 반복마다 커지게 된다. 두 번째 단계는 거의 Gradient Descent와 동일하지만 큰 차이가 있다. 기울기 벡터는 s + ε의 비율로 축소된다. 여기서 ε는 0으로 나누기를 피하기 위한 부드러운 항으로, 일반적으로 10^-10과 같은 작은 값으로 설정된다. 이러한 비율로 기울기 벡터를 축소하는 것은 학습률을 점차 감소시키는 효과를 낸다. 이는 기울기가 가파른 차원에서는 더 빠르게, 부드러운 경사를 가진 차원에서는 느리게 학습률이 줄어들게 된다.
이 알고리즘은 적응형 학습률을 사용하므로 가파른 차원으로 직접적으로 더 잘 향하게 한다. AdaGrad는 단순한 이차 문제에 대해 자주 잘 작동하지만, 신경망을 훈련할 때 종종 학습률이 너무 많이 감소하여 전역 최적점에 도달하기 전에 훈련이 완전히 중단될 수 있다. 따라서 Keras에는 Adagrad 옵티마이저가 있지만 이를 사용하여 심층 신경망을 훈련시키지 않는 것이 좋다.
RMSProp

optimizer = keras.optimizers.RMSproop(lr=0.001, rho=0.9)우리가 본 것처럼 AdaGrad는 속도가 너무 빨리 느려지고 전역 최적으로 수렴하지 않을 위험이 있다. RMSProp 알고리즘은 가장 최근 반복의 그래디언트만 누적하여 이 문제를 해결한다. 붕괴율 𝛽은 일반적으로 0.9로 설정된다.
Adam Optimization

optimizer = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999)적응형 모멘트 추정을 의미하는 Adam은 운동량 최적화와 RMSProp의 아이디어를 결합한 것이다. 이는 운동량 최적화와 마찬가지로 과거 기울기의 기하급수적으로 감소하는 평균을 추적하고 RMSProp과 마찬가지로 과거 제곱 기울기의 기하급수적으로 감소하는 평균을 추적한다.
Summary of Optimization
| Class | convergense speed(수렴 속도) | convergence quality(수렴 품질) |
| SGD | * | * * * |
| SGD(momentum=..) | * * | * * * |
| SGD(momentum=.., nesterov=True) | * * | * * * |
| Adagrad | * * * | *(stop too early) |
| RMSprop | * * * | * * or * * * |
| Adam | * * * | * * or * * * |
| Nadam | * * * | * * or * * * |
| AdaMax | * * * | * * or * * * |
학습률 스케줄링(Learning Rate Scheduling)

학습률은 중요한 요소로, 적절한 설정이 훈련의 성공에 영향을 미친다. 고정된 학습률은 문제가 될 수 있어, 학습 스케줄을 사용하는 것이 좋다. 여러 가지 학습 스케줄링 기법이 있다.
거듭제곱 스케줄 (Power scheduling)

optimizer = keras.optimizers.SGD(lr=0.01, decay=1e-4)반복 횟수 t의 함수로 학습률을 설정한다. 위 공식에서 𝜂0는 초기 학습률, c는 거듭제곱(일반적으로 1), s는 단계이다. 스텝이 지날 때마다 학습률이 빠르게 낮아지고, 일정 스텝 수가 지난 후에는 더 느리게 감소한다.
지수 스케줄 (Exponential scheduling)
# Exponential scheduling
def exponential_decay_fn(epoch):
return 0.01 * 0.1 ** (epoch / 20)
def exponential_decay(lr0, s):
def exponential_decay_fn(epoch):
return lr0 * 0.1 ** (epoch / s)
exponential_decay_fn = def exponential_decay(lr0 = 0.01, s = 20)
lr_scheduler = keras.callbacks.LearningRateScheduler(exponential_decay_fn)
history = model.fix(X_train_scaled, y_train, [...], callbacks=[lr_scheduler])학습률을 𝜂(𝑡𝑡) = 𝜂0 * 0.1^(t/s)로 설정한다. 학습률은 일정한 스텝마다 10배씩 감소한다. 거듭제곱 스케줄이 더 느리게 감소하는 반면, 지수 스케줄은 일정한 스텝마다 학습률을 10배씩 줄어든다.
분할 상수 스케줄 (Piecewise constant scheduling)
def piecewise_constant_fn(epoch):
if epoch < 5:
retrun 0.01
elif epoch < 15:
return 0.005
else:
return 0.001일정한 에폭 동안 상수 학습률을 사용하고, 그 후 더 작은 학습률로 전환한다. 예를 들어, 처음 5 에폭 동안은 𝜂𝜂0 = 0.1로 유지하고, 다음 50 에폭 동안은 𝜂𝜂1 = 0.001로 설정하고 이런 식이다.
성능 스케줄 (Performance scheduling)
lr_scheduler = keras.callbacks.ReduceLROnPlateau(factor = 0.5, patience = 5)일정한 주기로 검증 오차를 측정하고 오차가 더 이상 감소하지 않으면 학습률을 λ(하강률)만큼 줄어든다. 조기 종료와 비슷하게 검증 오차를 관찰하여 학습률을 동적으로 조절한다.
1사이클 스케줄 (1cycle scheduling)
초기 학습률을 증가시키고 학습의 중간 지점에서 감소시키며, 후반부에는 학습률을 여러 단계로 급격히 낮춘다. 초기에는 빠르게 진전하고, 중간에는 안정적인 수렴을 도모하며 후반부에는 정교한 조정을 시도하는 방법이다.
정규화를 통해 오버피팅 피하기(Avoiding Overfitting Through Regularization)
ℓ1 and ℓ2 Regularization
layer = keras.layers.Dense(100, activation="elu", kernel_initializer="he_normal", kernel_regularizer=keras.regularizers.l2(0.01))
from functools import partial
RegularizedDense = partial(keras.layers.Dense, activation = "elu", kernel_initializer="he_normal", kernel_regularizre = keras.regularizers.l2(0.01))
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28,28]),
RegularizedDense(300),
RegularizedDense(100),
RegularizedDense(10, activation="softmax", kernel_initializer="glorot_uniform")
])신경망의 연결 가중치를 제한하기 위해 ℓ2 정규화를 사용할 수 있으며, 희소 모델(많은 가중치가 0인)을 원하는 경우 ℓ1 정규화를 사용할 수 있다. l2() 함수는 정규화 손실을 계산하기 위해 훈련 중 각 단계에서 호출되는 정규화 도구를 반환한다. 이는 최종 손실에 추가된다.
Dropout

Dropout (드롭아웃)은 딥 뉴런 네트워크에서 가장 인기 있는 정규화 기법 중 하나이다. 각 훈련 단계에서 모든 뉴런(입력 뉴런 포함, 단, 출력 뉴런은 제외)은 일시적으로 '드롭아웃'될 확률 p를 가진다. 이는 해당 훈련 단계 동안 완전히 무시될 것이지만 다음 단계에서는 활성화될 수 있다. 여기서 p는 드롭아웃 비율로, 일반적으로 10%에서 50% 사이로 설정된다. 훈련 후에는 뉴런이 더 이상 드롭되지 않는다.
드롭아웃을 사용하면 뉴런들은 이웃 뉴런과 함께 적응할 수 없으며, 가능한 한 독립적으로 유용해야 한다. 또한 소량의 입력 뉴런에 지나치게 의존할 수 없으며, 모든 입력 뉴런에 주의를 기울여야 한다. 결과적으로 일부 입력의 작은 변경에 덜 민감한 더 견고한 네트워크가 생성된다.
드롭아웃의 힘을 이해하는 또 다른 방법은 각 훈련 단계에서 고유한 신경망이 생성된다는 것이다. 각 뉴런이 존재하거나 존재하지 않을 수 있기 때문에 드롭 가능한 뉴런의 총 수가 N이라면 총 2^N개의 가능한 신경망이 존재한다. 따라서 10,000개의 훈련 단계를 실행하면 본질적으로 10,000개의 서로 다른 신경망을 훈련시킨 셈이다. 이러한 신경망은 많은 가중치를 공유하지만 그럼에도 불구하고 모두 다르다. 결과적으로 얻어지는 신경망은 이러한 작은 신경망의 평균 앙상블로 볼 수 있다.
드롭아웃을 사용할 때 중요한 작은 기술적인 세부 사항이 하나 있다. 예를 들어 p가 50%인 경우, 테스트 중에는 뉴런이 훈련 중 평균적으로 연결되는 입력 뉴런의 두 배에 해당하게 된다. 이를 보상하기 위해 훈련 후에는 각 뉴런의 입력 연결 가중치를 0.5로 곱해주어야 한다. 이렇게 하지 않으면 각 뉴런은 네트워크가 훈련된 것보다 대략 두 배 큰 총 입력 신호를 받게 되어 좋은 성능을 내기 어렵다. 더 일반적으로 훈련 후에는 각 입력 연결 가중치를 킵 확률(1 - p)로 곱해주어야 한다.
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dropout(rate=0.2),
keras.layers.Dense(300, activation="elu", kernel_initializer="he_normal"),
keras.layers.Dropout(rate=0.2),
keras.layers.Dense(100, activation="elu", kernel_initializer="he_normal"),
keras.layers.Dropout(rate=0.2),
keras.layers.Dense(10, activation="softmax")
])드롭아웃은 Keras에서 간단하게 구현할 수 있다. 모델이 과적합되는 경우 드롭아웃 비율을 높이고, 훈련 세트가 충분히 학습되지 않는 경우에는 드롭아웃 비율을 낮추는 것이 좋다. 또한 큰 레이어에 대해 드롭아웃 비율을 높이고, 작은 레이어에 대해 낮추는 것도 도움이 될 수 있다. 드롭아웃은 수렴을 상당히 느리게 만들 수 있지만 적절하게 조정하면 보다 나은 모델을 얻을 수 있다.
Monte Carlo (MC) Dropout
2016년에 발표된 논문은 드롭아웃을 사용하는 몇 가지 더 많은 이유를 제시했다. 먼저, 해당 논문은 드롭아웃 네트워크(즉, 각 가중치 레이어 이전에 Dropout 레이어가 있는 신경망)와 근사 베이지안 추론 간의 깊은 연결을 수립하여 드롭아웃에 견고한 수학적 근거를 부여했다. 둘째, 저자들은 MC 드롭아웃이라는 강력한 기술을 소개했는데, 이는 훈련된 드롭아웃 모델의 성능을 향상시키기 위해 모델을 다시 훈련하거나 수정할 필요가 전혀 없으며, 모델의 불확실성을 훨씬 더 효과적으로 측정할 수 있을 뿐만 아니라 구현이 놀랍도록 간단하다.
y_probas = np.stack([model(X_test_scaled, training=True) for sample in range(100)])
y_proba = y_probas.mean(axis=0)이전에 훈련한 드롭아웃 모델을 다시 훈련하지 않고 성능을 향상시키는 MC 드롭아웃의 구현은 다음과 같다.
- 테스트 세트에 대해 training=True로 설정하여 Dropout 레이어를 활성화하고 100번의 예측을 수행한 후 이를 쌓는다.
- 드롭아웃이 활성화되어 있기 때문에 모든 예측은 다르다.
- predict()는 각 인스턴스당 하나의 행과 각 클래스당 하나의 열을 가진 행렬을 반환한다. 테스트 세트에는 10,000개의 인스턴스와 10개의 클래스가 있으므로 이는 [10000, 10] 모양의 행렬입니다. 이러한 행렬을 100개 쌓으므로 y_probas는 [100, 10000, 10] 모양의 배열이다.
- 첫 번째 차원 (axis=0)을 기준으로 평균을 내면 y_proba라는 단일 예측과 동일한 [10000, 10] 모양의 배열이 생성된다.
드롭아웃을 적용한 여러 예측의 평균화는 보통 드롭아웃을 끈 채로 한 번의 예측 결과보다 믿을 수 있는 몬테 카를로 추정을 제공한다.
# 클래스 5 (샌들), 클래스 7 (운동화), 클래스 9 (앵클 부츠)
# 드롭아웃 끈 상태에서 모델의 첫 번째 인스턴스
np.round(model.predict(X_test_scaled[:1], 2))
# array([[0.,0.,0.,0.,0.,0.,0.,0.01,0.,0.99], dtype=float32])
# 드롭아웃 켠 상태에서 모델의 첫 번째 인스턴스에서는
np.round(y_probas[:, :1], 2)
# array([[0.,0.,0.,0.,0.,0.14,0.,0.17,0.,0.68]],
# [[0.,0.,0.,0.,0.,0.16,0.,0.2,0.,0.64]],
# [[0.,0.,0.,0.,0.,0.02,0.,0.01,0.,0.97]],
# [...])
np.round(y_proba[:, :1], 2)
# array([[0.,0.,0.,0.,0.,0.22,0.,0.16,0.,0.62]]. dtype=float32)이를 기반으로 Fashion MNIST 테스트 세트의 모델 예측 비교해보자.
class MCDropout(keras.layers.Dropout):
def call(self, inputs):
return super().call(inputs, training=True)만약 모델에 특별한 훈련 중 동작하는 다른 레이어(예: BatchNormalization 레이어)가 포함되어 있다면 방금 수행한 것처럼 강제로 훈련 모드를 설정해서는 안된다. 대신, Dropout 레이어를 다음과 같이 대체해야 한다.
최대-노름 규제(Max-Norm Regularization)

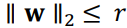
Max-Norm Regularization (최대-노름 규제)는 신경망에서 널리 사용되는 정규화 기법 중 하나로, 각 뉴런에 대해 들어오는 연결의 가중치를 특정 값으로 제한함으로써 모델의 일반화 성능을 향상시키는 목적을 가지고 있다. 이 기법은 ℓ2 노름을 활용하여 가중치 벡터의 크기를 제한한다. 구체적으로, 모든 가중치의 ℓ2 노름이 특정 값 r 이하가 되도록 제약을 두는데, 이때 r은 최대-노름 하이퍼파라미터로 설정된다.
최대-노름 규제는 전체 손실 함수에 새로운 정규화 항을 추가하지 않고, 각 훈련 단계 이후에 가중치 벡터의 ℓ2 노름을 계산하고 필요한 경우 조정함으로써 구현된다. 이렇게 함으로써 모델의 가중치가 특정 범위를 벗어나지 않도록 제한하게 되어 과적합을 억제하고 일반화 능력을 향상시킨다.
keras.layers.Dense(100, activation="elu", kernel_initializre="he_normal", kernel_constraint=keras.constrains.max_norm(1.))Keras에서는 간단하게 해당 노름을 조절하는 방식으로 최대-노름 규제를 적용할 수 있다. 이러한 정규화 기법은 과적합을 줄이고 안정적인 모델 학습을 도모하는 데 도움이 될 수 있다.
Summary and Practical Guidelines
기본 DNN 구성
| 하이퍼파라미터 | 기본 값 |
| Kernel initializer | He initialization |
| Activation function | ELU |
| Normalization | None if shallow; Batch Norm(깊을 경우) |
| Regularization | Early stopping (필요한 경우 ℓ2 reg. ) |
| Optimizer | Momentum optimization(or RMSProp or Nadam) |
| Learning rate schedule | 1cycle |
자체 정규화 네트워크를 위한 DNN 구성
| 하이퍼파라미터 | 기본 값 |
| Kernel initializer | LeCun initialization |
| Activation function | SELU |
| Normalization | None(self-normalization) |
| Regularization | Alpha dropout(필요한 경우) |
| Optimizer | Momentum optimization(or RMSProp or Nadam) |
| Learning rate schedule | 1cycle |
'컴퓨터공학 > AI' 카테고리의 다른 글
| AI를 배우기 전 행렬 이론 기초 (2) | 2024.03.14 |
|---|---|
| 기계학습 12. Convolutional Neural Networks(CNN) (2) | 2023.12.12 |
| 기계학습 10. Introduction to Artificial Neural Networks(ANN) (0) | 2023.12.01 |
| 기계 학습 9. Unsupervised Learning Techniques (1) | 2023.11.17 |
| 기계 학습 8. 차원 축소(Dimensionality Reduction) (0) | 2023.10.28 |




댓글