서론
컨볼루션 신경망(Convolutional neural networks, CNNs)은 뇌의 시각 피질 연구에서 비롯되어 이미지 인식 분야에서 1980년대부터 사용되어 왔다. 지난 몇 년 동안 계산 능력의 증가, 이용 가능한 훈련 데이터 양의 증가, 그리고 깊은 신경망을 훈련하기 위한 기술적인 기교들이 발전함에 따라, CNNs는 어려운 시각 작업에서 초인간적인 성능을 달성하는 데 성공했다. 뿐만 아니라, CNNs는 시각 인식에 국한되지 않고 음성 인식 및 자연어 처리와 같은 다양한 작업에서도 성공적으로 활용되고 있다.
Convolutional Layers

첫 번째 컨볼루션 레이어(Convolution Layers)의 뉴런들은 입력 이미지의 모든 픽셀과 직접 연결되지 않으며, 오직 각 뉴런은 자신의 수용 영역(receptive fields)에 속한 픽셀들과만 연결된다. 그리고 두 번째 컨볼루션 레이어의 각 뉴런은 첫 번째 레이어 내에서 작은 직사각형에 위치한 뉴런들과만 연결된다. 이러한 구조는 네트워크가 첫 번째 은닉 레이어에서 작은 저수준 특징에 집중한 후, 다음 은닉 레이어에서 이를 조합하여 더 큰 고수준 특징을 형성할 수 있도록 한다. 또한 CNN에서 각 레이어는 2D로 표현되어 있어 뉴런과 해당 입력을 쉽게 매칭할 수 있다.
CNN에서 각 레이어는 이전 레이어의 뉴런 출력에 연결되는데, 특정 레이어에서 위치한 행 𝑖 및 열 𝑗에 있는 뉴런은 이전 레이어의 행 𝑖부터 𝑖 + 𝑓ℎ– 1, 열 𝑗부터 𝑗 + 𝑓𝑤– 1에 위치한 뉴런들과 연결된다. 여기서 𝑓ℎ 및 𝑓𝑤는 수용 영역의 높이와 너비를 나타낸다. 레이어가 이전 레이어와 동일한 높이와 너비를 가져야 하는 경우, 입력 주변에 패딩을 추가하여 수용 영역을 벗어나지 않도록 한다. 이를 '제로 패딩'(Zero Padding)이라고 한다.
또한 수용 영역을 희소하게 배치함으로써 큰 입력 레이어를 훨씬 작은 레이어에 연결할 수도 있다. 이 때 다음 수용 영역으로의 이동은 '스트라이드'(stride)라고 불린다. 예를 들어, 5 × 7 입력 레이어(제로 패딩 포함)가 3 × 4 레이어에 3 × 3 수용 영역과 스트라이드 2를 사용하여 연결된다. 상위 레이어에서 특정 행 𝑖, 열 𝑗에 위치한 뉴런은 이전 레이어의 행 𝑖 × 𝑠ℎ부터 𝑖 × 𝑠ℎ + 𝑓ℎ– 1, 열 𝑗 × 𝑠𝑤부터 𝑗 × 𝑠𝑤 + 𝑓𝑤 − 1에 위치한 뉴런들과 연결된다. 여기서 𝑠ℎ와 𝑠𝑤는 수직 및 수평 스트라이드이다.
필터(Filters)
뉴런의 가중치는 수용 영역의 크기와 동일한 작은 이미지로 나타낼 수 있다. 이를 필터(filters or convolution kernels)라고 한다. 예를 들어, 세로 필터는 중앙 열을 제외한 모든 요소가 0인 7 × 7 행렬로 나타낼 수 있다. 이 가중치를 사용하는 뉴런은 수용 영역 내의 중앙 세로 선을 제외한 모든 것을 무시할 것이다.(중앙 세로 선에 위치한 입력만이 0이 아닌 값과 곱해지기 때문) 수평 필터는 수직 필터의 수평 버전이다. 한 레이어의 모든 뉴런이 동일한 세로 선 필터를 사용하는 경우, 해당 레이어는 이미지에서 세로 흰 선이 강조된 결과를 출력하게 된다. 반대로, 수평 필터는 수평 선에 대해 동일한 작용을 한다. 따라서 동일한 필터를 사용하는 뉴런으로 가득 찬 레이어는 해당 필터를 가장 활성화하는 이미지 영역을 강조하는 특성 맵을 출력한다. 이러한 필터를 수동으로 정의할 필요가 없으며, 대신 합성곱 레이어는 훈련 중에 자동으로 해당 작업에 가장 유용한 필터를 학습하고, 상위 레이어는 이를 더 복잡한 패턴으로 결합하는 방식으로 학습한다.
Stacking Multiple Feature Maps(여러 특성 맵 쌓기)
합성곱 레이어(convolutional layer)는 여러 필터를 사용하여 각 필터 당 하나의 특성 맵을 출력함으로써 3D로 더 정확하게 표현된다. 각 특성 맵은 각각의 픽셀에 대한 뉴런을 가지며, 동일한 특성 맵 내의 모든 뉴런은 동일한 매개변수(가중치 및 편향 항)를 공유한다. 이는 매개변수 수를 현저하게 감소시키며 한 위치에서 패턴을 학습한 경우 다른 위치에서도 해당 패턴을 인식할 수 있게 한다.
합성곱 레이어는 여러 훈련 가능한 필터를 동시에 적용하여 입력의 어디에서든 다양한 기능을 감지할 수 있도록 한다. 또한 입력 이미지는 여러 색상 채널을 가지고 있으며, 각 채널은 하나의 하위 레이어에 해당한다. 이러한 다양한 채널은 빨강, 초록, 파랑(RGB) 등의 색상을 나타내거나, 흑백 이미지의 경우 하나의 채널만을 가지게 된다.
특정 합성곱 레이어의 뉴런 출력을 계산하는 방법은 가중 합계와 편향 항을 더하는 것으로, 이를 통해 다양한 입력에서 특정 패턴을 감지할 수 있다. 각 특성 맵은 모델이 특정 패턴 또는 특징을 인식하도록 학습하는 데 기여하며, 이러한 특성 맵은 서로 다른 채널과 필터에 대응하여 다양한 시각적 정보를 포착한다.
TensorFlow로 구현하기
from sklearn.datasets import load_sample_image
# 샘플 이미지 로드하기
china = load_sample_image("china.jpg") / 255
flower = load_sample_image("flower.jpg") / 255
images = np.array([china, flower])
batch_size, height, width, channels = images.shape
# 2개 필터 만들기
filters = np.zeros(shape=(7, 7, chennel, 2), dtype=np.float32)
filters[:, 3, :, 0] = 1 # 수직 필터
filters[3, :, :, 1] = 1 # 수평 필터
outputs = tf.nn.conv2d(images, filters, strides = 1, padding = "SAME")
plt.imshow(output[0, :, :, 1], cmap="gray")
plt.show()TensorFlow에서 각 입력 이미지는 일반적으로 [높이, 너비, 채널] 모양의 3D 텐서로 표현된다. 미니배치까지 포함할 시 [미니배치 크기, 높이, 너비, 채널] 모양의 4D 텐서로 표현된다. 합성곱 레이어의 가중치는 [필터 높이, 필터 너비, 입력 채널 수, 출력 채널 수] 모양의 4D 텐서로 나타낸다. 합성곱 레이어의 편향은 단순히 [출력 채널 수] 모양의 1D 텐서로 표현된다. 윗 코드는 두 개의 샘플 이미지를 로드하고(중국 사원과 꽃 이미지), 두 필터를 생성하여 이미지에 적용하고, 마지막으로 생성된 특성 맵 중 하나를 표시하는 과정을 보여준다. 이 예제에서는 필터를 수동으로 정의했지만, 일반적으로 실제 CNN에서는 가중치를 학습할 수 있도록 훈련 가능한 변수로 정의한다. `keras.layers.Conv2D` 레이어를 사용하여 필터를 정의할 수 있다. 합성곱 레이어는 많은 하이퍼파라미터를 가지고 있습니다. 필터의 개수, 높이와 너비, 스트라이드 및 패딩 유형 등이 그 중 일부이다.
conv = keras.layers.Conv2D(filters=32, kernel_size = 3, strides = 1, padding = "same", activation = "relu")메모리 요구 사항
CNN의 또 다른 문제점은 합성곱 레이어가 많은 양의 RAM을 필요로 한다. 이는 특히 훈련 중에 해당되는데, 역전파의 역방향 패스에서는 순방향 패스 동안 계산된 모든 중간 값이 필요하다.
예를 들어, 5 × 5 필터를 사용하는 합성곱 레이어를 생각해보자. 이 레이어는 150 × 100 크기의 200개 특성 맵을 출력하며, 스트라이드는 1이고 "same" 패딩을 사용한다고 가정하자. 만약 입력이 150 × 100 RGB 이미지(세 개의 채널)라면, 파라미터 수는 (5 × 5 × 3 + 1) × 200 = 15,200이며 (여기서 +1은 편향(bias) 항에 해당함) 이는 완전히 연결된 레이어(fully connected layer)에 비해 상당히 작다. 그러나 200개의 특성 맵 각각은 150 × 100 뉴런을 포함하며, 각각의 뉴런은 5 × 5 × 3 = 75개의 입력에 가중 합을 계산해야 한다. 이는 총 2억 2천 5백만 번의 부동 소수점 곱셈을 의미한다. 완전히 연결된 레이어만큼 심하지는 않지만 여전히 상당히 계산량이 많다. 더구나, 32비트 부동 소수점을 사용하여 특성 맵을 표현한다면 합성곱 레이어의 출력은 200 × 150 × 100 × 32 = 9600만 비트(12MB)의 RAM을 차지할 것이다. 이것은 하나의 인스턴스에 대한 것일 뿐이며, 훈련 배치에 100개의 인스턴스가 포함되어 있다면 이 레이어는 1.2GB의 RAM을 사용한다.
추론(새로운 인스턴스에 대한 예측 수행) 중에는 한 레이어가 계산된 즉시 해당 레이어가 차지한 RAM을 해제할 수 있어서 두 연속 레이어에 필요한 만큼의 RAM만 필요하다. 그러나 훈련 중에는 순방향 패스 동안 계산된 모든 값이 역방향 패스를 위해 보존되어야 하므로 필요한 RAM 양은 적어도 모든 레이어에 필요한 총 RAM 양이다. 만약 훈련 중에 메모리 부족 오류로 인해 훈련이 실패한다면 다음과 같은 방법을 생각해보자.
- 미니배치 크기를 줄여 볼 수 있다.
- 또는 스트라이드를 사용하여 차원을 줄이거나 몇 개의 레이어를 제거해 볼 수 있다.
- 32비트 부동 소수점 대신 16비트 부동 소수점을 사용해 볼 수 있다.
- 또는 CNN을 여러 장치에 분산하여 사용해 볼 수 있다.
Pooling Layers
Pooling 레이어의 목표는 계산 부하, 메모리 사용량, 그리고 매개변수 수를 줄여서(과적합의 위험을 제한하는 데 도움이 되는) 입력 이미지를 하향 샘플링(즉, 축소)하는 것이다. 합성곱 레이어와 마찬가지로 풀링 레이어의 각 뉴런은 이전 레이어의 제한된 수의 뉴런의 출력에 연결되며, 이는 작은 직사각형 수용 영역 내에 위치한다. 크기, 스트라이드 및 패딩 유형을 정의해야 하며, 이는 이전과 마찬가지로 진행된다. 그러나 풀링 뉴런은 가중치가 없다. 그저 최대값 또는 평균과 같은 집계 함수를 사용하여 입력을 집계하는 것뿐이다.
최대 풀링 레이어는 작은 이동에 대한 어느 정도의 불변성(invariance)을 도입한다. CNN에서 매 몇몇 레이어마다 최대 풀링 레이어를 삽입하면 큰 규모에서 어느 정도의 이동 불변성을 얻을 수 있다. 또한, 최대 풀링은 약간의 회전 불변성과 약간의 크기 불변성을 제공한다. 이러한 불변성은(비록 제한적일지라도) 예측이 이러한 세부 사항에 의존하지 않아야 하는 경우에 유용할 수 있다. 그러나 최대 풀링에는 몇 가지 단점이 있다. 첫째, 아주 작은 2 × 2 커널과 2의 스트라이드로도 출력은 양방향으로 2배 작아질 것이다.(따라서 면적은 4배 작아진다) 즉, 입력 값의 75%를 간단히 삭제된다. 둘째, 어떤 응용에서는 불변성이 원하지 않을 수 있다. 시맨틱 세그멘테이션(이미지의 각 픽셀을 해당 픽셀이 속한 객체에 따라 분류하는 작업으로 나중에 이 장에서 살펴볼 것이다)을 생각해보면 입력 이미지가 오른쪽으로 한 픽셀 이동하면 출력도 오른쪽으로 한 픽셀 이동해야 한다. 이 경우 목표는 무변이 아닌 동질성(equivariance)이다. 입력의 작은 변화는 출력에서 대응하는 작은 변화로 이어져야 한다.
max_pool = keras.layers.MaxPool2D(pool_size = 2)위 코드는 2 × 2 커널을 사용하여 최대 풀링 계층을 생성한다. 스트라이드의 기본값은 커널 크기이므로 이 레이어에서는 2(수평 및 수직 모두)의 스트라이드를 사용한다. 기본적으로 "valid" 패딩을 사용한다.(즉, 패딩이 전혀 없음) 평균 풀링 레이어를 생성하려면 MaxPool2D 대신 AvgPool2D를 사용하자.
CNN Architectures
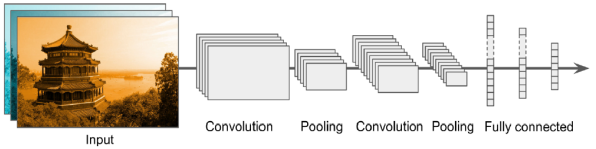
전형적인 CNN 아키텍처는 일반적으로 여러 합성곱 레이어(각각은 일반적으로 ReLU 레이어 뒤에 따르는)를 쌓고, 그 다음에 풀링 레이어, 그 다음에 또 다른 합성곱 레이어(+ReLU), 그리고 이를 반복하는 구조이다. 이미지는 네트워크를 통과함에 따라 작아지지만 일반적으로 더 깊어지기도 한다.(더 많은 특징 맵을 가지게 됨) 스택 맨 위에는 일반적인 피드포워드 신경망(feedforward neural network)이 추가되며, 이는 몇 개의 완전 연결 레이어(+ReLU)로 구성되고 최종 레이어는 예측을 출력한다.(예: 소프트맥스 레이어를 통해 추정된 클래스 확률을 출력)
model = keras.model.Sequential([
keras.layers.Conv2D(64, 7, activation="relu", padding="same", input_shape=[28, 28, 1]),
keras.layers.MaxPooling2D(2),
keras.layers.Con2D(128, 3, activation="relu", padding="same"),
keras.layers.Con2D(128, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Con2D(256, 3, activation="relu", padding="same"),
keras.layers.Con2D(256, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Flatten(),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dropout(0.5),
keras.layers.Dense(64, activation="relu"),
keras.layers.Dropout(0.5),
keras.layers.Dense(10, activation="relu"),
])Fashion MNIST 데이터셋을 처리하기 위한 간단한 CNN의 예시로, 여기에서 주목해야 할 점은 합성곱 레이어가 쌓일수록 필터의 수가 증가한다는 것이다(초기에는 64개, 그런 다음 128개, 그 다음 256개). 이는 필터의 수가 증가하는 것이 합리적이다. 낮은 수준의 특성의 수는 일반적으로 상당히 적기 때문이다.(예: 작은 원, 수평선) 그러나 이러한 특성을 고수준의 기능으로 결합하는 방법은 매우 다양하므로 뒤에 나오는 레이어에서는 필터 수를 두 배로 늘리는 것이 일반적이다. 왜냐하면 풀링 레이어가 각 공간 차원을 2로 나누기 때문에 다음 레이어에서 특징 맵의 수를 두 배로 늘릴 수 있기 때문이다. 이로 인해 매개변수, 메모리 사용량, 또는 계산 부하가 급격하게 증가하지 않을 수 있다.
LeNet-5
1998년 Yann LeCun에 의해 만들어졌으며 필기 숫자 인식(MNIST)에 널리 사용되었다.

AlexNet

AlexNet은 Alex Krizhevsky, Ilya Sutskever 및 Geoffrey Hinton에 의해 개발되었으며 2012 ImageNet ILSVRC 챌린지에서 큰 차이로 1등을 차지했다. 상위 다섯 에러율이 17%로, 두 번째로 높은 성적은 26%, 즉 9%라는 큰 차이의 성능을 보여주었다. 이는 LeNet-5와 유사하지만 훨씬 크고 깊으며, 첫 번째로 합성곱 레이어를 직접 쌓는 방식을 도입했다. 각 합성곱 레이어 위에 풀링 레이어를 쌓는 대신에 직접 쌓았다. 과적합을 줄이기 위해 AlexNet의 저자들은 두 가지 정규화 기술(드롭아웃(dropout)과 데이터 증가(data augmentation))을 사용했다.
데이터 증가(data augmentation)는 학습 세트의 크기를 인위적으로 증가시키는 기술로, 각 학습 인스턴스의 여러 현실적인 변형을 생성함으로써 이루어진다. 간단히 흰 소음을 추가하는 것만으로는 도움이 되지 않는다. 수정 사항은 학습 가능해야 한다.(흰 소음은 그렇지 않는다) 예를 들어, 학습 세트의 각 사진을 다양한 양만큼 약간 이동, 회전 및 크기 조정하고 결과 사진을 학습 세트에 추가할 수 있다. 이는 모델이 사진 내 객체의 위치, 방향 및 크기의 변화에 대해 더 관대해지도록 강제한다. 다양한 조명 조건에 대해 더 관대한 모델을 위해 다양한 대비로 많은 이미지를 생성할 수 있다. 일반적으로 사진을 수평으로 뒤집을 수도 있다.(텍스트 및 기타 비대칭 객체를 제외하고) 이러한 변환을 결합하여 교육 세트의 크기를 크게 증가시킬 수 있다.

입력값 227에서 11필터를 사용하므로 빼주면 216, Stride가 4를 사용하므로 4로 나눠주면 54, 마지막으로 bias를 1을 더해주면 55가 된다. pooling에 경우 사이즈를 반으로 줄여준다.
GoogLeNet
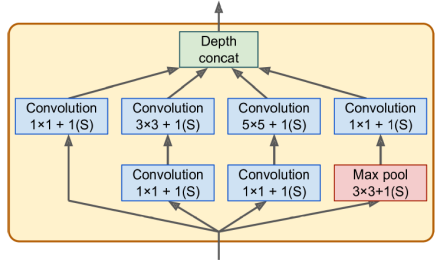

GoogLeNet은 Google Research의 Christian Szegedy 등에 의해 개발되었으며 ILSVRC 2014 챌린지에서 상위 다섯 에러율을 7% 미만으로 낮추면서 우승했다. 이 뛰어난 성능은 네트워크가 이전 CNN보다 훨씬 깊었다는 사실에서 큰 부분을 차지했다. 이는 인셉션 모듈(inception modules)이라 불리는 서브네트워크 덕분에 가능했는데, 이 모듈들을 통해 GoogLeNet은 이전 아키텍처보다 훨씬 효율적으로 매개변수를 사용할 수 있게 되었다. 실제로 GoogLeNet은 AlexNet보다 10배 적은 매개변수를 가지고 있다.
인셉션 모듈은 여러 다른 레이어에 입력 신호를 복사하고 전달한다. 모든 합성곱 레이어는 ReLU 활성화 함수를 사용한다. 두 번째 합성곱 레이어 세트는 다른 커널 크기(1 × 1, 3 × 3 및 5 × 5)를 사용하여 서로 다른 스케일의 패턴을 캡처할 수 있게 한다. 각 레이어는 모두 1의 스트라이드와 "same" 패딩을 사용하므로 출력은 모두 입력과 동일한 높이와 너비를 가지게 된다. 이로써 최종적인 깊이 연결 레이어에서 깊이 차원을 따라 모든 출력을 연결할 수 있게 된다.
1x1 커널을 사용하는 인셉션 모듈의 이유는 무엇일까? 이러한 레이어는 공간 패턴을 캡처할 수 없을 텐데, 정말로는 하나의 픽셀만을 살펴볼 수 있기 때문일 것이다. 실제로 이러한 레이어는 세 가지 목적을 제공한다. 먼저 공간 패턴을 캡처할 수는 없지만 깊이 차원을 따라 패턴을 캡처할 수 있다. 둘째로 입력보다 적은 특징 맵을 출력하도록 구성되어 있으므로 병목 레이어로 작동하여 차원을 감소시킨다. 이는 계산 비용과 매개변수 수를 줄여 학습 속도를 높이고 일반화를 향상시킨다. 세 번째로 [1 × 1, 3 × 3] 및 [1 × 1, 5 × 5]의 각 쌍의 합성곱 레이어는 더 복잡한 패턴을 캡처할 수 있는 단일 강력한 합성곱 레이어처럼 작동한다. 사실 단일 합성곱 레이어가 이미지를 가로지르는 간단한 선형 분류기를 휘감는 대신, 이 두 합성곱 레이어 쌍은 이미지를 가로지르는 2층 신경망을 휘감게 된다.
VGGNet
2014년 옥스퍼드 대학교 VGG(Visual Geometry Group) 연구소의 Karen Simonyan과 Andrew Zisserman이 개발했으며 ILSVRC 2014 챌린지에서 준우승했다. VCGNet은 2~3개의 콘볼루션 레이어와 1개의 풀링 레이어, 그리고 다시 2~3개의 콘볼루션 레이어와 1개의 풀링 레이어 등으로 구성된 매우 단순하고 고전적인 아키텍처를 갖고 있다.(상태에 따라 총 16~19개의 콘볼루션 레이어에 도달) VGG variant), 2개의 숨겨진 레이어와 출력 레이어가 있는 최종 밀집 네트워크이다. 3×3 필터만 사용했지만 많은 필터를 사용했다.
ResNet (Residual Network)

ResNet(Residual Network)은 Kaiming He 등에 의해 개발되었으며 ILSVRC 2015 챌린지에서 놀라운 상위 다섯 에러율인 3.6% 미만을 달성하면서 우승했다. 이는 152개 레이어로 구성된 극도로 깊은 CNN이다. 이러한 깊은 네트워크를 훈련할 수 있는 핵심은 스킵 연결(skio connections or shortcut sonnections)을 사용하는 것이다. 특정 레이어로 들어오는 신호는 스택 상위에 있는 레이어의 출력에 더해진다.

일반적인 신경망을 초기화하면 가중치가 거의 0에 가깝기 때문에 네트워크는 단순히 0에 가까운 값만 출력한다. 그러나 스킵 연결을 추가하면 결과적인 네트워크는 입력의 복사본만 출력한다. 다시 말해, 초기에는 신원 함수(identity function)를 모델링한다. 목표 함수가 신원 함수와 상당히 가까울 경우 훈련 속도가 크게 향상된다.
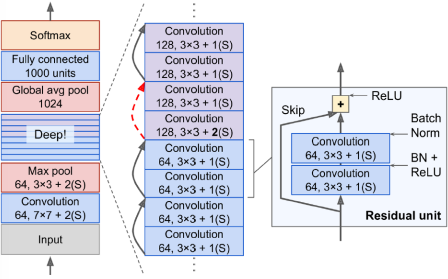
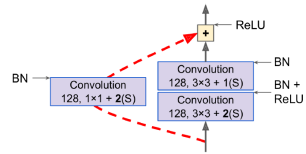
게다가 많은 스킵 연결을 추가하면 여러 레이어가 아직 학습을 시작하지 않았더라도 네트워크가 진전을 나타낼 수 있다. 특이한 점은 몇 개의 잔여 유닛마다 특징 맵의 수가 두 배로 늘어나면서 동시에 높이와 너비가 절반이 된다.(스트라이드 2를 사용하는 합성곱 레이어 사용) 이렇게 되면 입력은 같은 모양을 가지지 않기 때문에 잔여 유닛의 출력에 직접 더할 수 없다. 이 문제를 해결하기 위해 입력은 1×1 합성곱 레이어를 거쳐 스트라이드 2 및 올바른 수의 출력 특징 맵을 가진다.
Xception
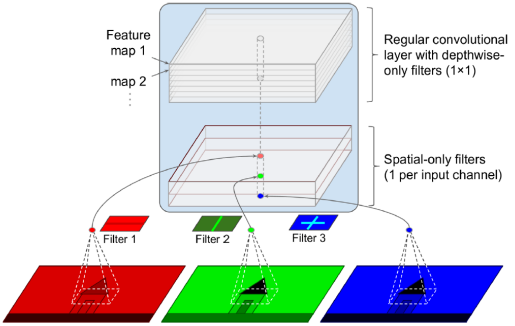
Xception은 GoogLeNet 아키텍처의 또 다른 변형으로 2016년에 Francois Chollet (Keras의 저자)에 의해 제안되었다. Xception19(Extreme Inception의 약어)은 거대한 비전 작업(3억 5000만 개의 이미지 및 17,000개의 클래스)에서 Inception-v3보다 큰 성과를 내었다. Xception은 GoogLeNet과 ResNet의 아이디어를 통합하지만 inception 모듈을 depthwise separable convolution layer(또는 separable convolution layer로 줄여짐)라고 불리는 특수한 유형의 레이어로 대체한다. 일반적인 합성곱 레이어는 동시에 공간 패턴(예: 타원)과 교차 채널 패턴(예: 입 + 코 + 눈 = 얼굴)을 캡처하려고 하는 필터를 사용하는 반면, separable convolutional layer는 공간 패턴과 교차 채널 패턴을 별도로 모델링할 수 있다는 가정을 기반으로 한다.
Depthwise separable convolution layer는 두 부분으로 구성된다. 첫 번째 부분은 각 입력 특징 맵에 대해 단일 공간 필터를 적용하고, 두 번째 부분은 교차 채널 패턴만 찾는다. 이는 1×1 필터가 있는 일반적인 합성곱 레이어일 뿐이다. Xception 아키텍처는 2개의 일반 합성곱 레이어로 시작하지만 나머지 아키텍처는 모두 separable convolution(총 34개)과 몇 개의 맥스 풀링 레이어, 그리고 전형적인 최종 레이어(글로벌 평균 풀링 레이어 및 밀집 출력 레이어)만 사용한다.
SENet (Squeeze-and-Excitation Network)

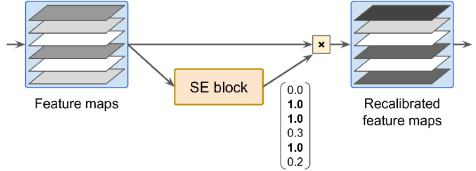
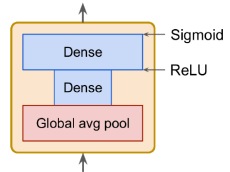
SENet은 Squeeze-and-Excitation Network의 약어로, 2017년 ILSVRC 챌린지에서 2.25%의 top-five 에러율로 우승한 아키텍처이다. 이 아키텍처는 inception 네트워크와 ResNet과 같은 기존 아키텍처를 확장하고 성능을 향상시킨다. SE 블록은 해당 유닛의 출력을 분석하고 깊이 차원에 집중하여 기능 맵을 재교정하는 데 사용된다. 이 블록은 공간 패턴을 찾지 않고 깊이 차원에서 가장 활동적인 특징이 어떤 것인지 학습하고 이 정보를 사용하여 기능 맵을 재교정한다.
Implementing a ResNet-34 CNN using Keras
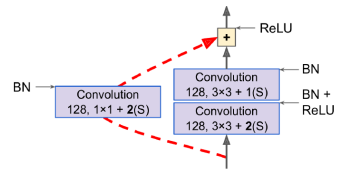
class ResidualUnit(keras.layers.Layer):
def __init__(self, filters, strides=1, activation="relu", **kwargs):
super().__init__(**kwargs)
self.activation = keras.activations.get(activation)
self.main_layers = [
keras.layers.Con2D(filters, 3, strides=strides, padding="same",use_bias=False),
keras.layers.BatchNormalization(),
self.activation,
keras.layers.Con2D(filters, 3, strides=1, padding="same", use_bias=False),
keras.layers.BatchNormalization()]
self.skip_layers = []
if strides > 1:
self.skip_layers = [
keras.layers.Con2D(filters, 1, strides=strides, padding="same", use_bias=False),
keras.layers.BatchNormalization()]
def call(self, inputs):
Z = inputs
for layer in slef.main_layers:
Z = layer(Z)
skip_Z = inputs
for layer in self.skip_layers:
skip_Z = layer(skip_Z)
return self.activation(Z + skip_Z)
model = kreas.models.Sequential()
model.add(keras.layers.Con2D(64, 7, strides=2, input_shape=[224, 224, 3], padding="same", use_biase=False))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation("relu"))
model.add(keras.layers.MaxPool2D(pool_size=3, strides=2, padding="same"))
prev_filters = 64
for filters in [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3:
strides = 1 if filters == prev_filters else 2
model.add(RedisualUnit(filters, strides=strides))
prev_filters = filters
model.add(keras.layers.GlobalAvgPool2D())
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(10, activation="softmax"))Using Pretrained Models from Keras
model = keras.applications.resnet50.ResNet50(weights="imagenet")
images_resized = tf.image.resize(images, [224, 224])
inputs = keras.applications.resnet50.preprocess_input(images_resized * 255)
Y_proba = model.predict(inputs)
import tensorflow_datasets as tfds
dataset, info = tfds.load("tf_flowers", as_supervised=True, with_info=True)
dataset_size = info.splits["train"].num_examples # 3670
class_names = info.features["label"].names # ["dandelion", "daisy", ...]
n_classes = info.features["label"].num_classes # 5
test_split, valid_split, train_split = tfds.Split.TRAIN.sibsplit([10, 15, 75])
test_set = tfds.load("tf_flowers", split=test_split, as_supervised=True)
valid_set = tfds.load("tf_flowers", split=valid_split, as_supervised=True)
train_set = tfds.load("tf_flowers", split=train_split, as_supervised=True)
def preprocess(image, label):
resized_image = tf.image.resize(image, [224, 224])
final_image = keras.applications.xception.preprocess_input(resized_image)
return final_image, label
batch_size = 32
train_set = train_set.shuffle(1000)
train_set = train_set.map(preprocess).batch(batch_size).prefetch(1)
valid_set = valid_set.map(preprocess).batch(batch_size).prefetch(1)
test_set = test_set.map(preprocess).batch(batch_size).prefetch(1)
base_model = keras.applications.xception.Xception(weights="imagenet", include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
output = keras.layers.Dense(n_classes, activation="softmax")(avg)
model = keras.Model(inputs=base_model.input, outputs=output)
for layer in base_model.layers:
layer.trainable = False # True
optimizer = keras.optimizers.SGD(lr=0.2, momentum=0.9, decay=0.01)
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"])
history = model.fit(train_set, epochs = 5, validation_data=valid_set)Applications
Classification and Localization

base_model = keras.applications.xception.Xception(weights="imagenet", include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
class_output = keras.layers.Dense(4)(avg)
model = keras.Model(inputs=base_model.input, outputs=[class_output, loc_output])
model.compile(loss=["spares_categorical_crossentropy", "mse"], loss_weights = [0.8, 0.2], optimizer=optimizer, metrics=["accuracy"])분류 및 위치 지정은 객체를 사진에서 찾아내어 해당 객체 주위에 경계 상자를 예측하는 회귀 작업으로 표현할 수 있다. 일반적인 방법은 객체의 중심의 수평 및 수직 좌표, 그리고 높이와 너비를 예측하는 것이다. 이를 위해 전형적으로 글로벌 평균 풀링 레이어 위에 네 개의 유닛을 가진 두 번째 밀집 출력 레이어를 추가하면 된다. 그리고 이 레이어는 MSE 손실을 사용하여 훈련될 수 있다. 이미지에 경계 상자를 주석 처리하려면 VGG Image Annotator, LabelImg, OpenLabeler, ImgLab와 같은 오픈 소스 이미지 레이블링 도구를 사용하거나 LabelBox나 Supervisely와 같은 상용 도구를 사용할 수 있다. 경계 상자에 대한 가장 일반적인 지표는 Intersection over Union (IoU)이며, 예측된 경계 상자와 대상 경계 상자 간의 겹치는 영역을 그들의 합집합의 영역으로 나눈 것이다.
Object Detection
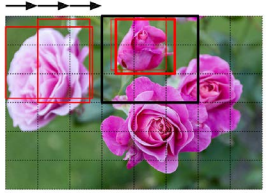
객체 감지(Object Detection)는 이미지에서 여러 객체를 분류하고 지역화하는 작업을 말한다. 몇 년 전까지 일반적인 접근법은 단일 객체를 분류하고 찾는 데 훈련된 CNN을 가져와서 이미지를 슬라이딩하는 것이었다. 또한 객체의 크기가 다양할 수 있기 때문에 다양한 크기의 영역을 CNN 위로 슬라이딩했다. 이 기술은 꽤 직관적이지만 같은 객체를 약간 다른 위치에서 여러 번 감지할 것이다.
객체 감지에 대한이 단순한 접근 방식은 잘 작동하지만 CNN을 여러 번 실행해야 하므로 상당히 느리다. 다행히도 이미지를 슬라이딩하는 더 빠른 방법이 있다. Fully Convolutional Network (FCN, 완전 합성곱 신경망)을 사용하는 것이다.
Fully Convolutional Networks (FCNs)
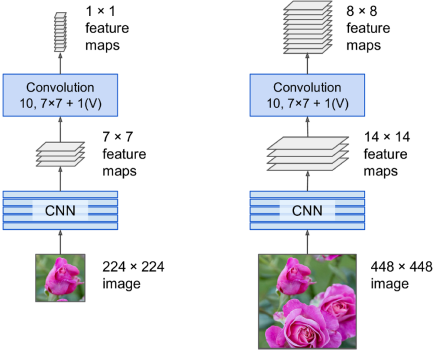
FCN의 아이디어는 2015 년 Jonathan Long 등에 의해 처음 소개되었으며 시맨틱 세그멘테이션(이미지의 모든 픽셀을 해당 객체 클래스에 따라 분류하는 작업)을 위한 것이었다. 이 아이디어는 CNN의 상단에있는 밀집 레이어를 컨볼루션 레이어로 대체할 수 있다는 것이다. 예를 들어 200 개의 뉴런이있는 밀집 레이어가 100 개의 특징 맵을 출력하는 컨볼루션 레이어 위에 있다고 가정해 보자. 각 특징 맵의 크기는 7 × 7이다. 컨볼루션 레이어에서 제공된 모든 100 × 7 × 7 활성화에 대한 가중 합계를 각 뉴런이 계산할 것이다.(바이어스 항 포함) 밀집 레이어를 크기가 7 × 7이고 "valid" 패딩을 사용하는 컨볼루션 레이어로 대체하면 이 레이어는 200 개의 특징 맵을 출력하게 된다. 이들은 각각 1 × 1 크기이며 ("valid" 패딩을 사용하므로) 입력 특징 맵과 같은 깊이를 가지게 된다. 다시 말해 이들은 밀집 레이어에서 생성 된 것과 정확히 동일한 숫자를 출력할 것이다. 유일한 차이점은 밀집 레이어의 출력이 [배치 크기, 200] 모양의 텐서 였다면 컨볼루션 레이어는 [배치 크기, 1, 1, 200] 모양의 텐서를 출력할 것이다.
이것이 중요한 이유는 밀집 레이어는 특정한 입력 크기를 기대하는 반면, 컨볼루션 레이어는 이미지를 어떤 크기로든 처리할 수 있다는 것이다. FCN은 컨볼루션 레이어(및 동일한 특성을 가진 pooling 레이어)만 포함하므로 어떤 크기의 이미지에 대해 훈련 및 실행될 수 있다.
You Only Look Once (YOLO)
YOLO는 Joseph Redmon 등이 2015 년에 제안한 극히 빠르고 정확한 객체 감지 아키텍처로, 이후 2016 년(YOLOv2) 및 2018 년(YOLOv3)에 개선되었다. YOLOv3 아키텍처는 각 그리드 셀 당 다섯 개의 바운딩 박스를 출력하며(단일 개체만 출력하는 대신), 각 바운딩 박스는 객체 존재 여부에 대한 점수를 포함한다. 또한 PASCAL VOC 데이터 세트에서 훈련되었으며 각 그리드 셀 당 20 개의 클래스 확률을 출력한다. 이는 그리드 셀 당 45 개의 숫자로 구성된다. 5 개의 바운딩 박스 각각에는 4 개의 좌표, 5 개의 객체 여부 점수, 20 개의 클래스 확률이 포함되어 있다. YOLOv3는 K-Means 알고리즘을 훈련 세트 바운딩 박스의 높이와 너비에 적용하여 다섯 개의 대표적인 바운딩 박스 차원을 찾는다. 네트워크는 다양한 크기의 이미지를 사용하여 훈련되며 훈련 중에 모든 배치마다 네트워크는 새 이미지 크기를 무작위로 선택한다(330 × 330에서 608 × 608 픽셀까지). 이렇게 하면 네트워크가 다양한 크기에서 객체를 감지하는 것을 학습할 수 있다.
Mean Average Precision (mAP)

객체 감지 작업에서 사용되는 매우 일반적인 지표는 평균 평균 정밀도(mAP)이다. 예측기가 10% 리콜에서 90% 정밀도를 가지고 있지만 20% 리콜에서는 96% 정밀도를 가질 경우를 가정해 보자. 정밀도 / 리콜은 상충 관계에 있지만 정밀도가 증가함에 따라 리콜이 증가하는 몇 가지 섹션도 있다. 객체 감지 시스템에서 정밀도와 리콜의 트레이드 오프가 있을 때 효과적인 모델 성능을 얻기 위해 최소 0% 리콜, 그리고 10%, 20% 등을 포함하여 최소 100% 리콜까지 사용하여 최대 정밀도를 계산하고 이러한 최대 정밀도의 평균을 계산하는 것이 일반적이다. 이것이 평균 정밀도 (Average Precision, AP) 메트릭이라고한다. 더 나아가 두 개 이상의 클래스가있는 경우 각 클래스에 대해 AP를 계산하고 이러한 최대 정밀도의 평균을 계산하여 평균 정밀도(mean Average Precision, mAP)를 얻을 수 있다.
객체가 정확한 클래스를 감지하지만 잘못된 위치에 있을 때 (즉, 바운딩 박스가 완전히 벗어난 경우) 객체 감지 시스템에서 이를 어떻게 처리할까? 일반적으로 IOU(Intersection over Union) 임계값을 정의하여 예측이 정확한 경우를 고려한다. 예를 들어 IOU가 0.5보다 크면서 예측된 클래스가 올바른 경우에만 예측이 올바른 것으로 간주한다. 이에 해당하는 mAP는 일반적으로 mAP@0.5로 표시된다.
Semantic Segmentation


시맨틱 세그멘테이션은 각 이미지 픽셀이 해당 객체의 클래스에 따라 분류되는 컴퓨터 비전 작업이다.(예: 도로, 자동차, 보행자, 건물 등) 객체 감지와 달리 시맨틱 세그멘테이션은 동일한 클래스의 다른 객체를 구분하지 않고, 각 픽셀에 클래스 레이블을 지정하는 데 중점을 둔다.
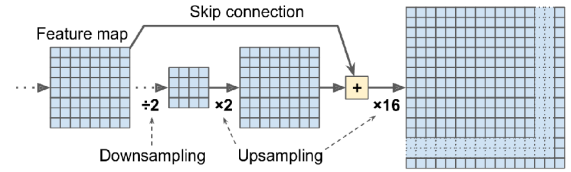
시맨틱 세그멘테이션의 주요 어려움은 전통적인 합성곱 신경망(CNN)이 이미지가 네트워크를 통과함에 따라 공간 해상도를 감소시킨다는 사실에서 비롯된다. 결과적으로 일반적인 CNN은 특정 영역에 객체가 존재함을 나타낼 수 있지만 그 이상의 정밀도가 부족하다. 이 문제를 해결하기 위해 Jonathan Long 등이 2015 년에 제안한 솔루션은 사전 훈련된 CNN을 완전 합성곱 네트워크(FCN)로 변환하는 것이다. 원래의 CNN은 입력 이미지에 대해 전체적으로 32의 스트라이드를 적용하여 최종 레이어의 피처 맵이 입력 이미지보다 32 배 작아진다. 해상도를 높이기 위해 단일 업샘플링 레이어가 추가되어 해상도를 32 배로 증가시킨다.
전치 합성곱 레이어(Transposed convolutional layer), 또는 업샘플링 레이어로도 알려진 레이어는 업샘플링을 위해 사용된다. 이 레이어는 이미지를 늘리기 위해 빈 행과 열(0으로 채워진)을 삽입한 다음 일반적인 합성곱을 수행하는 것과 동일하다. 이 접근 방식은 해상도를 향상시키지만 여전히 정밀성이 부족할 수 있다.
세분화 정확도를 더 향상시키기 위해 작성자는 낮은 레이어에서부터 스킵 연결을 도입했다. 이러한 스킵 연결은 이전 풀링 레이어에서 손실된 일부 공간 해상도를 회복한다. 이 아키텍처를 사용하면 고수준 의미 정보와 세부적인 공간 기능을 모두 포착하여 더 정확한 시맨틱 세그멘테이션 결과를 얻을 수 있다.
참고
- 최근에는 7 * 7 필터보다 3 * 3 필터를 두 번 쌓는 것이 더욱 효율적이기에 3 * 3 필터를 주로 사용한다.
'컴퓨터공학 > AI' 카테고리의 다른 글
| 인공지능 1. 퍼셉트론 (0) | 2024.04.01 |
|---|---|
| AI를 배우기 전 행렬 이론 기초 (2) | 2024.03.14 |
| 기계학습 11. Training Deep Neural Networks (1) | 2023.12.01 |
| 기계학습 10. Introduction to Artificial Neural Networks(ANN) (0) | 2023.12.01 |
| 기계 학습 9. Unsupervised Learning Techniques (1) | 2023.11.17 |




댓글