서론
퍼셉트론 이론은 인공지능 분야의 초석을 이루는 중요한 개념이다. 본 블로그는 퍼셉트론의 기본 원리, 구현 방법, 그리고 이론의 한계점을 포괄적으로 다룬다. 또한, 퍼셉트론의 한계를 극복하기 위한 확률 생성 모델, 손실 함수의 통계적 해석, 베르누이 분포 및 교차 엔트로피에 대해서도 상세히 설명한다. 이를 통해 독자들은 퍼셉트론 이론의 깊이 있는 이해는 물론, 인공지능 모델 설계에 있어서의 중요한 개념들을 파악할 수 있을 것이다.
퍼셉트론
퍼셉트론은 인공 신경망의 가장 기본적인 요소로, 간단한 입력을 받아 출력을 결정하는 알고리즘이다. 1957년 프랑크 로젠블라트(Rosenblatt)에 의해 처음 소개된 이후, 퍼셉트론은 인공지능 연구에 있어 기본적인 빌딩 블록으로 자리 잡았다. 본 소개에서는 퍼셉트론의 기본 원리와 인공지능 분야에서의 중요성에 대해 알아보자.
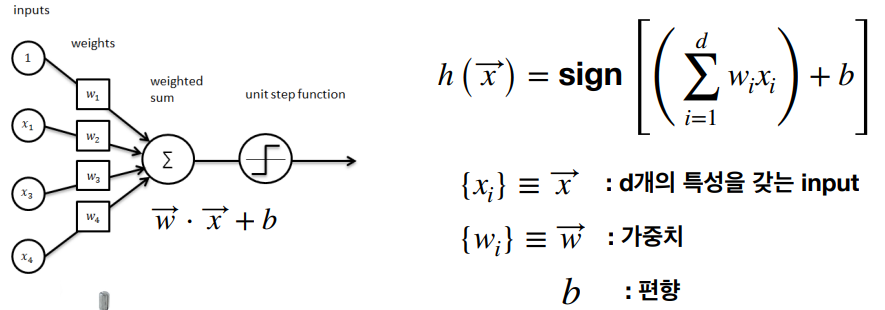
구현
퍼셉트론의 구현은 상대적으로 단순하다. 여러 입력에 가중치를 곱한 후, 합산하여 어떤 임계값을 넘으면 활성화되는 구조를 갖는다. 이를 통해 기본적인 분류 문제를 해결할 수 있다. 아래는 직선 (선형관계식)을 사용하여, OR-gate와 AND-gate를 구현을 간략히 시각화한 것이다.
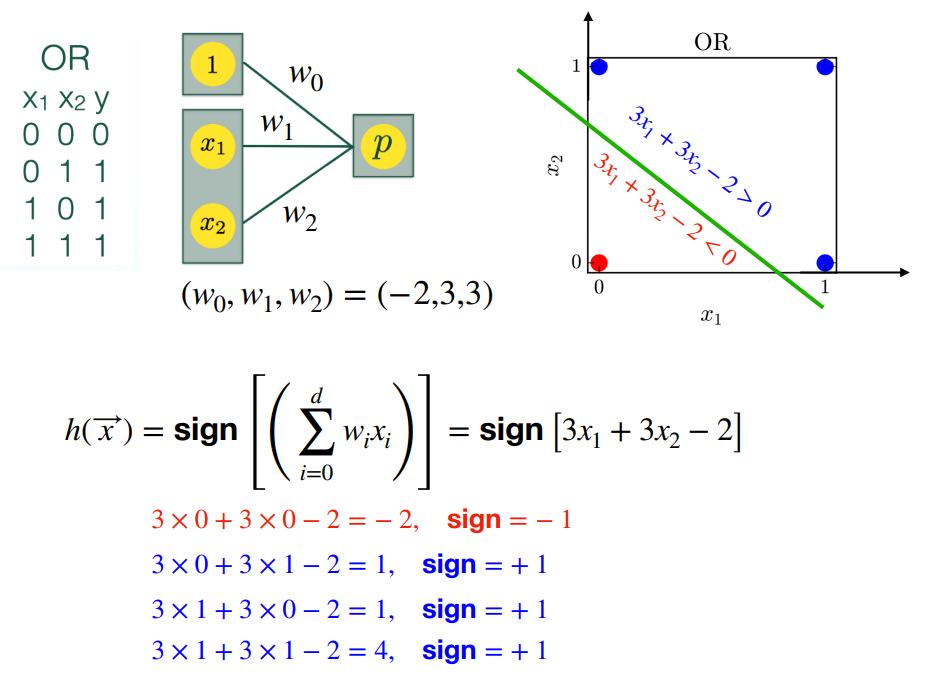
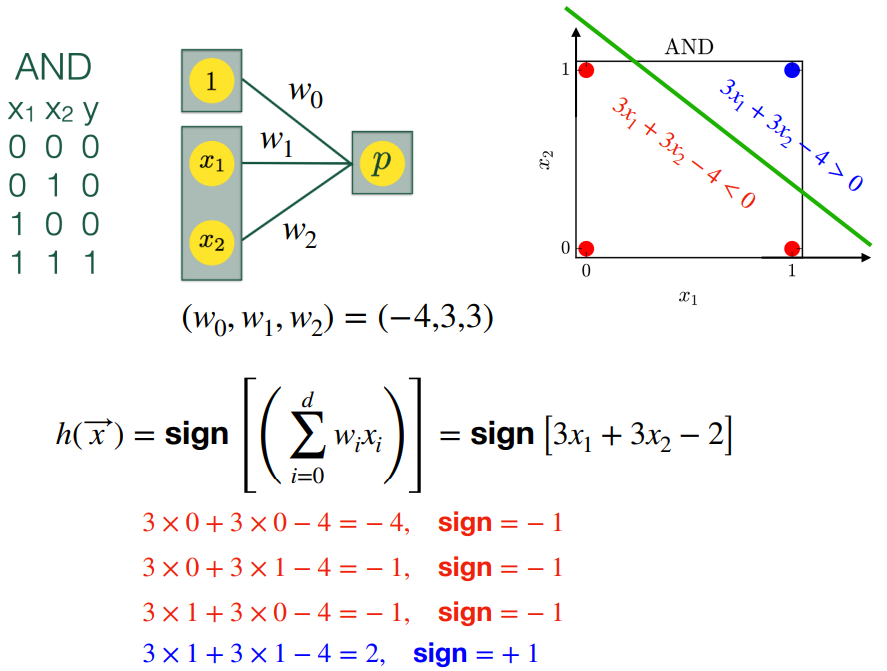
가중치 설정 방법 (확률적 방법을 사용하는 알고리즘):
1. 임의로 가중치 → w를 설정한다.
2. →w에 의해 잘못 분류된 값인 →xk임의의 를 선택한다. 이 경우, 잘못 분류된 값은 yk→w→x < 0을 만족한다.
3. →w’ = →w + yk*→xk로 가중치 →w를 업데이트한다.
4. 업데이트된 가중치 →w’은 yk’→xk > yk→w*→xk을 만족한다.
5. 즉, 업데이트된 가중치는 분류의 올바른 방향으로 경계면을 움직인다.
학습을 너무 tight 하게 할 경우, 시험에서 실패할 수도 있음.
=> margin (여유)를 고려하여 경계면을 설정
SVM (Support Vector Machine): 학습할 때, 여유를 최대화할 수 있는 경계면 설정
한계
그러나 기본적인 분류 문제를 해결할 수 있으나, XOR 문제와 같이 선형 분리가 불가능한 경우에는 적합하지 않다. 이러한 한계를 극복하기 위해 다층 퍼셉트론과 같은 개념이 도입되었으며, 이는 인공지능 연구에 새로운 장을 열었다.

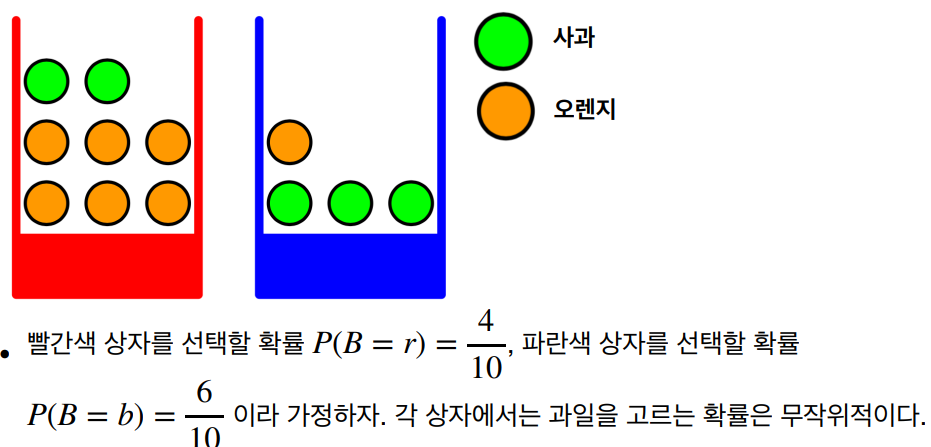
확률 생성 모델
확률 생성 모델은 데이터가 특정 확률 분포를 따른다고 가정하고, 이를 기반으로 데이터를 생성하거나 분류하는 모델이다.
조건부 확률 P(X|Y) = Y를 관측했을 때 X 일 확률
클래스 (K)가 여러 개가 있는 경우, 즉 K > 2


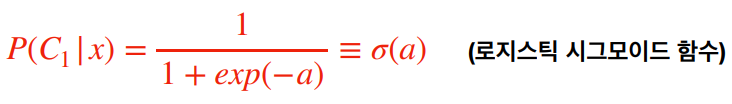

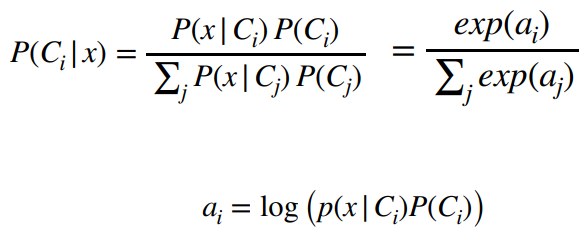
손실 함수
확률 생성 모델과 관련하여, 손실 함수는 모델의 예측이 실제 데이터와 얼마나 잘 일치하는지를 측정하는 지표로, 통계적 해석을 통해 모델의 성능을 개선할 수 있다.
최대 가능도법 (Maximum likelihood method) 관측된 데이터를 바탕으로 모델의 파라미터 (parameter)를 추측할 수 있다. 파라미터에 따른 모델이 예측하는 것과, 관측된 데이터와 일치할 가능성을 최대일 때를 찾을 수 있다. 즉, 관측된 사건의 발생확률을 최대로 만드는 모델 파라미터를 찾는 과정이다.
#손실함수 (Loss function) : 지도학습에서 예측값과 관측값의 차이
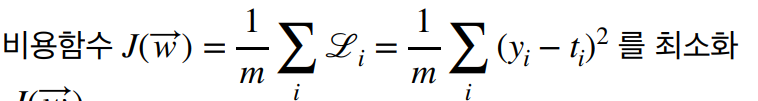
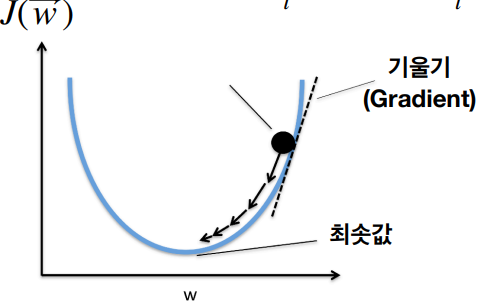

특히, 베르누이 분포와 교차 엔트로피는 이진 분류 문제에서 중요한 역할을 하며, 이들의 이해는 퍼셉트론을 포함한 다양한 인공지능 모델을 설계하는 데 있어 필수적이다.


주섬주섬
인공지능을 더 쉽게 알려주기 위해 작성한 글이다. 만약 상세히 알고 싶다면 아래 글을 참고하길 바란다.
참고
keras
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
# 퍼셉트론 코드에서 작성한 데이터 파일을 읽기
import numpy as np
output=np.load('perceptron_data.npz')
output.files
# 학습에 필요한 데이터의 크기 정함
N_train = 1000
N_test = 100
train_set_X=output['train_set_X'][:, :N_train]
train_set_Y=output['train_set_Y'][:, :N_train]
test_set_X=output['test_set_X'][:, :N_test]
test_set_Y=output['test_set_Y'][:, :N_test]
print(train_set_X.shape)
print(train_set_Y.shape)
print(test_set_X.shape)
print(test_set_Y.shape)
# Neural Network에서 output의 출력을 -1 > 0 그리고, 1 > 1로 하기 위한 전처리 작업
train_set_Y_ONE=np.heaviside(train_set_Y, 0)
test_set_Y_ONE=np.heaviside(test_set_Y, 0)
# Keras에서 데이터의 포맷은 (데이터 번호, 각 데이터의 특성) 으로 되므로, 행렬의 Transpose를 이용해 데이터 구조를 변환
train_set_keras_X=np.transpose(train_set_X)
test_set_keras_X=np.transpose(test_set_X)
train_set_keras_Y_ONE=np.transpose(train_set_Y_ONE)
test_set_keras_Y_ONE=np.transpose(test_set_Y_ONE)
print(train_set_keras_X.shape)
print(train_set_keras_Y_ONE.shape)
from tensorflow.keras import models
from tensorflow.keras import layers
model=models.Sequential()
model.add(layers.Dense(1, input_dim=2, activation='sigmoid')) # feature가 2개인 데이터를 입력
model.summary()
model.compile(optimizer='adam',loss='mse',metrics=['accuracy'])
Result= model.fit(train_set_keras_X,train_set_keras_Y_ONE,epochs=20, batch_size=10, validation_data=(test_set_keras_X, test_set_keras_Y_ONE))
import matplotlib.pyplot as plt
history_dict= Result.history
loss = history_dict['loss']
val_loss = history_dict['val_loss']
accuracy = history_dict['accuracy']
val_accuracy = history_dict['val_accuracy']
epochs = range(1, len(loss)+1)
plt.figure(figsize=(10, 4))
plt.subplot(121)
plt.plot(epochs, loss, 'bo',label='training loss')
plt.plot(epochs, val_loss, 'b', label='test loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(122)
plt.plot(epochs, accuracy, 'bo',label='training accuracy')
plt.plot(epochs, val_accuracy, 'b', label='test accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.show()강화 학습 1.기본 개념
서론 강화학습은 머신러닝과 다른 길로 발전을 하다, AI라는 큰 분야로 통합이 되면서 합쳐진 분야이다. 그렇기에 대충 이야기할 때는 머신러닝이 강화학습의 일부분처럼 말한다.(물론 머신러닝
jinger.tistory.com
기계 학습 1.기본 개념
서론 머신 러닝(Machine Learning)은 데이터로부터 학습하는 컴퓨터 과학의 한 분야이다. 최근에 AI가 많은 관심을 받고 있다. 이 기술은 최근에 만들어진 개념이 아니라, 과거부터 존재했던 개념이다
jinger.tistory.com
'컴퓨터공학 > AI' 카테고리의 다른 글
| 인공지능 3. 단층 신경망 (1) | 2024.04.07 |
|---|---|
| 인공지능 2. 기초 최적화 이론 (0) | 2024.04.05 |
| AI를 배우기 전 행렬 이론 기초 (2) | 2024.03.14 |
| 기계학습 12. Convolutional Neural Networks(CNN) (0) | 2023.12.12 |
| 기계학습 11. Training Deep Neural Networks (1) | 2023.12.01 |




댓글